
今回は、SQLの代表的な集合演算子[UNION][EXCEPT][INTERSECT]について、それぞれの概要を初心者向けに解説します。
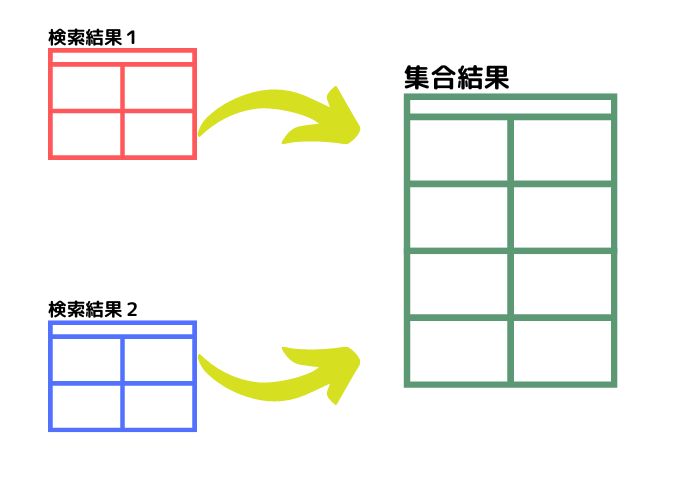
集合演算子は、RDBMSの基本概念であるテーブル構造の検索結果同士を1つの結果にまとめるために使われます。ただし、元々、違うテーブルからの検索結果同士のため、重複するデータが含まれている場合の扱いなど、用途に応じて考えなければなりません。
この記事では、SQLの集合演算子について、ベン図と呼ばれる集合の関係を表す図を用いて説明します。
SQLの集合演算子の基本
SQLの集合演算子は、2つの異なるテーブルからの検索結果を1つにまとめるときに使います。
集合の条件
集合演算子を使って1つにまとめるためには、2つの検索結果のデータ構造が一致していなければなりません。具体的には、それぞれの検索結果の列数とデータ型が完全に一致していることが集合の条件となります。
補足ですが、あくまでも列数とデータ型の完全一致が求められるのは、検索結果に対してです。
列数等が異なるテーブル同士でも、SELECT〜WHEREの検索結果で列数とデータ型が一致していれば、集合演算子を使って1つにまとめることができます。
SQLの集合演算子について
SQLの代表的な集合演算子は、[UNION]、[EXCEPT]、[INTERSECT]の3つです。この章では、それぞれの集合演算子の概要について説明します。
UNION(和集合)
まずは、集合演算子の中でも最もシンプルかつ代表的な[UNION]です。UNIONは和集合の仕組みの集合演算子で、2つの検索結果を単純にまとめます。
集合後の検索結果には、下記のデータがすべて存在します。
- Aテーブルからの検索結果だけにあるデータ
- Bテーブルからの検索結果にだけあるデータ
- Aテーブル、Bテーブル両方の検索結果にあるデータ

UNION(和集合)の結果、重複するデータがある場合には、その重複データを1行にまとめるか、それぞれ抽出するかについては、SQL文で操作することができます。

EXCEPT(差集合)
次に[EXCEPT]です。EXCEPTは差集合の仕組みの集合演算子で、1つ目の検索結果を元に、2つ目の検索結果に存在するデータを差し引いたものが集合結果となります。
つまり、EXCEPT(差集合)の結果は1つ目の検索結果のみに存在するデータのみが残ります。たとえば、今月新規で発生した費目などを抽出するときに使います。


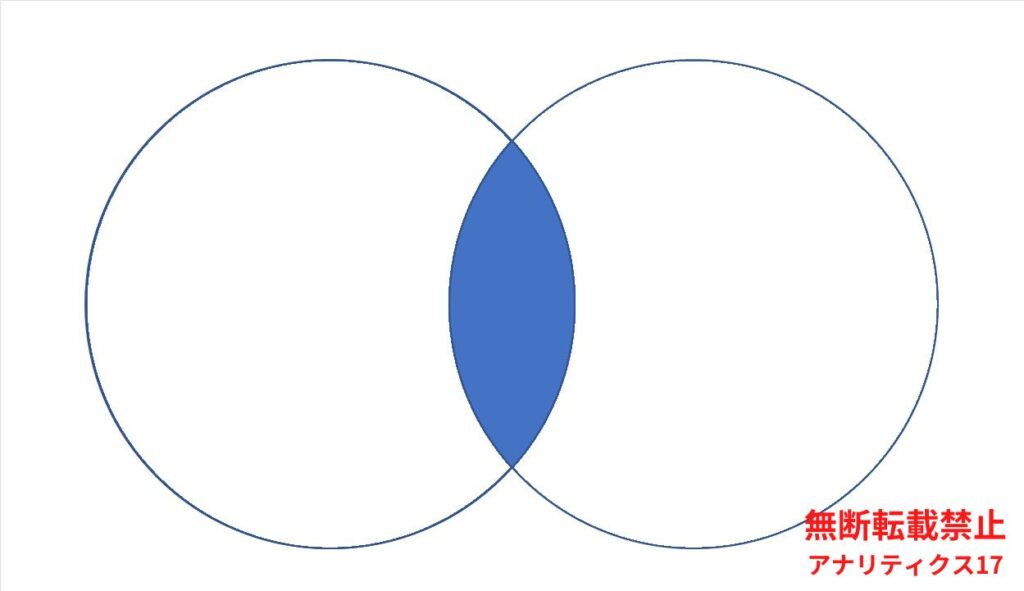
INTERSECT(積集合)
最後に、[INTERSECT]です。INTERSECTは積集合の仕組みの集合演算子で、1つ目の検索結果と2つ目の検索結果に存在する共通データのみが集合結果となります。

あとがき
今回は、SQLの集合演算子の概要について、それぞれのベン図を用いて説明しました。
当記事では概要のみの説明となりますが、実際のSQL文や実例については、別記事で説明します。まずは、集合演算子の基本となる3つのパターンについて、イメージを正確に理解しておきましょう。