
Googleが提供するクラウド型のデータウェアハウスサービス[BigQuery]。
BigQueryは、パソコンにインストールすることなくWebブラウザを通じて使うことができます。そして、Googleの他のサービス同様、Googleアカウントがあれば、初期登録も難しいことはありません。
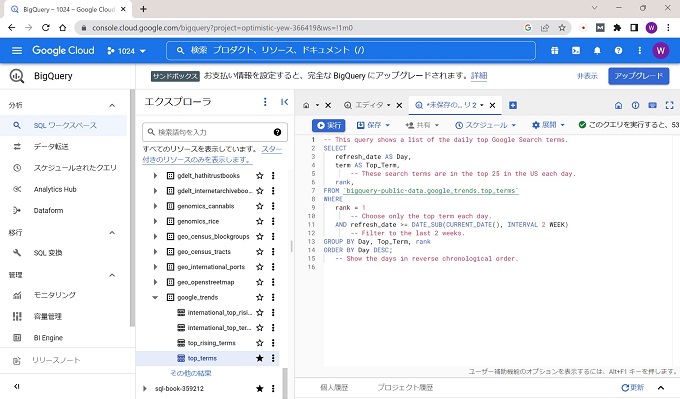
この記事では、GoogleのBigQueryの基本的な使い方を初期登録の手順を含めて説明します。
BigQueryの初期登録(始め方)
BigQueryを無料で使う(試す)ための方法には、[Google Cloud Platformの無料トライアル]と[BigQueryサンドボックス]の2通りがあります。
それぞれのプランの詳細と料金体系については、別記事で説明します

この章では、無期限で使えるBigQueryサンドボックスの始め方について説明します。
BigQueryサンドボックスの利用開始
普段、お使いのまたはBigQueryを使う予定のGoogleアカウントでログインした状態で始めてください。ブラウザの種類は問いませんが、BigQueryはGoogleのサービスのため、Chromeがベストでしょう。
(https://cloud.google.com/bigquery/docs/sandbox/?hl=ja)
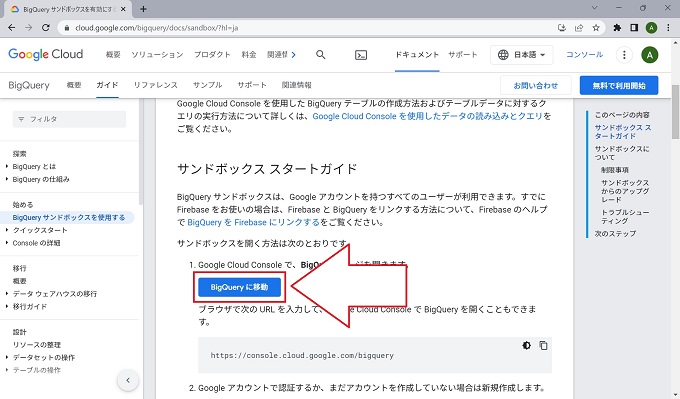
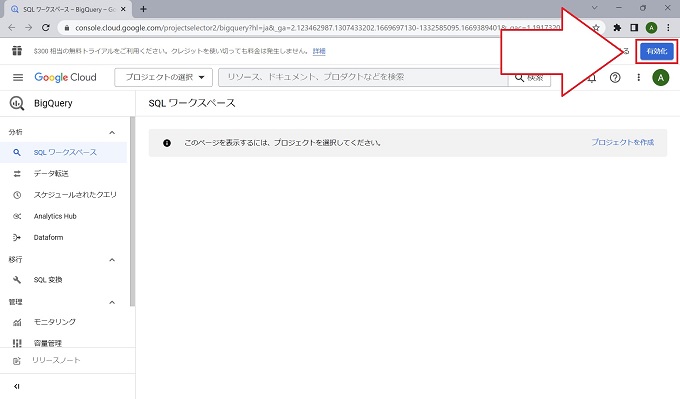
上記③のイメージ図の右上にある[有効化]のボタンは、Google Cloud Platformの無料トライアルを有効化するためのボタンです。このままBigQueryのサンドボックスを使い続けるのであれば、クリックする必要はありません。
以上、BigQueryのサンドボックスの初期登録(始め方)の手順です
BigQueryサンドボックスでは、テーブルの有効期間が60日間に制限されています。60日を経過した場合、予告もなく削除されますので、お気をつけください。
BigQueryの基本的な使い方
この章では、BigQueryの基本的な使い方を説明します。なお、BigQueryではSQL言語をメインに使いますので、SQLの知識があることが前提です。
BigQueryの階層構造
BigQueryでは、まずプロジェクトを作成することから始まります。プロジェクトには、複数のデータセットを作成することが可能で、さらにデータセットには複数のテーブルを作成することが可能です。
下記のうち、データセットがRDBMSでいう「データベース」に該当します。

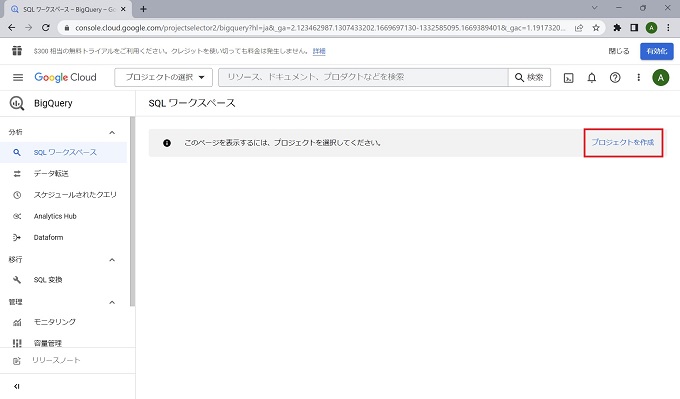
プロジェクトの作成
まずは、BigQueryでプロジェクトを作成します。
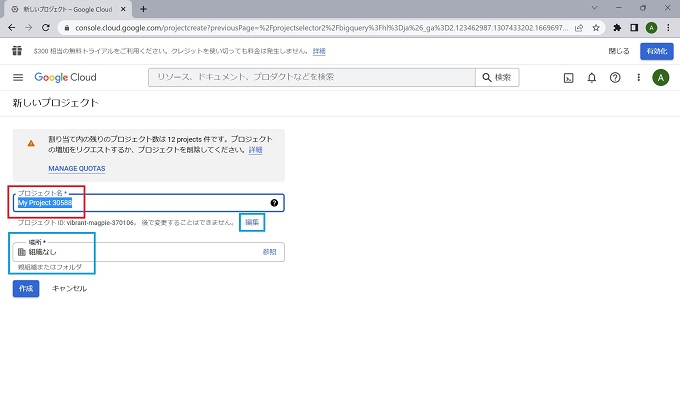
※プロジェクトIDや場所は特に理由がなければデフォルトでよい
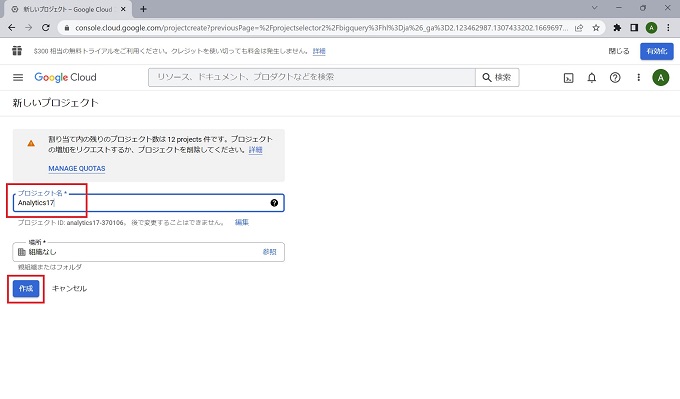
作成ボタンをクリック
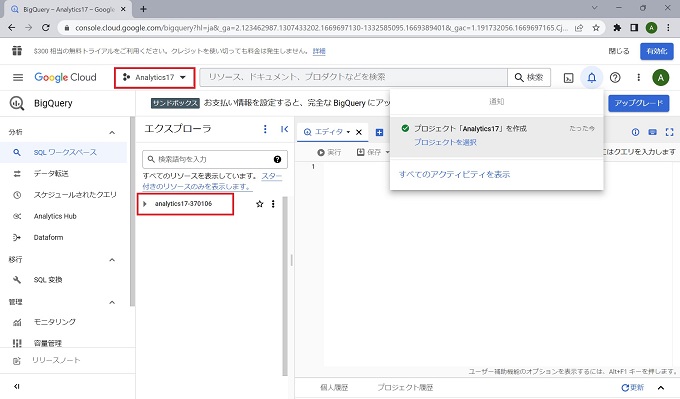
以上、BigQueryのプロジェクトの作成手順です。引き続き、データセットを作成します(次節)。
データセットの作成
前節で作成したプロジェクト内にデータセットを作成します。当章の[BigQueryの階層構造]で説明した通り、データセットはRDBMSのデータベースに該当し、複数のテーブルやビューの格納先になります。
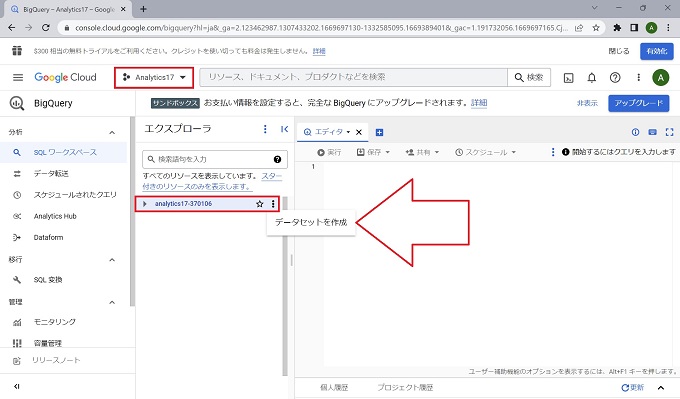
その後、データセットを作成をクリック
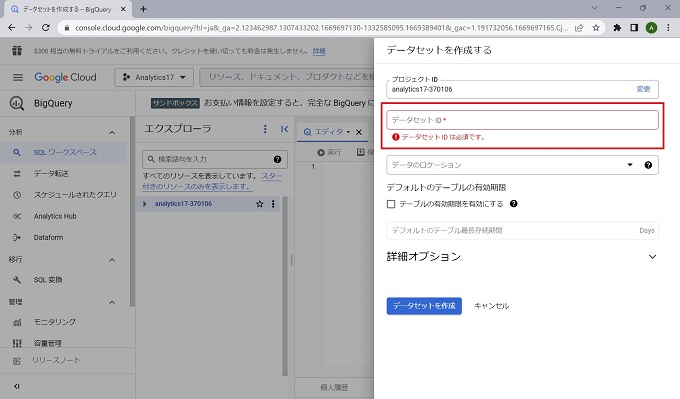
※その他の項目は必須ではなく特に設定不要
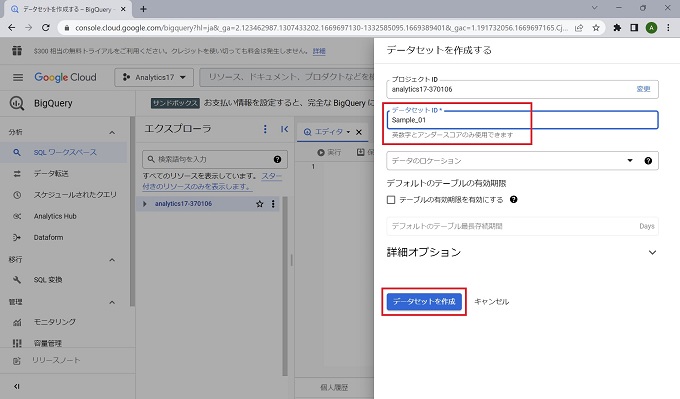
データセットを作成ボタンをクリック
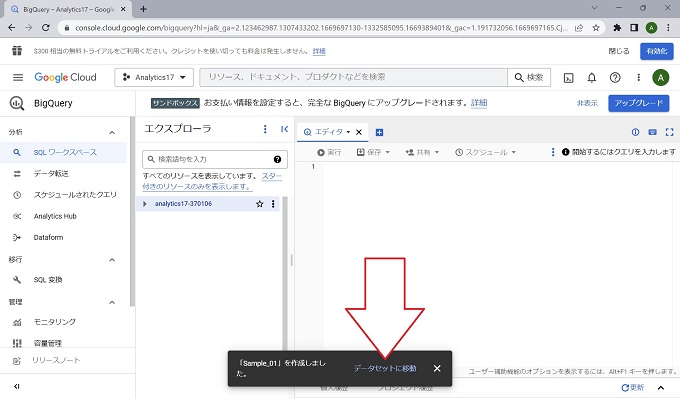
イメージ図④のメッセージウィンドウを閉じてしまっても、下記のようにデータセットを開くことができます。
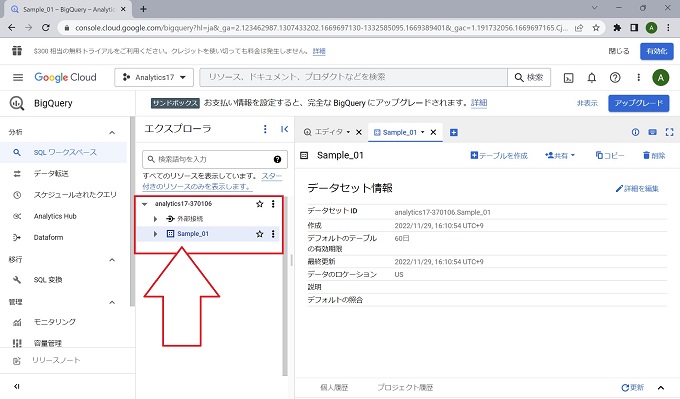
以上、BigQueryのデータセットの作成手順です。引き続き、テーブルを作成します(次節)。
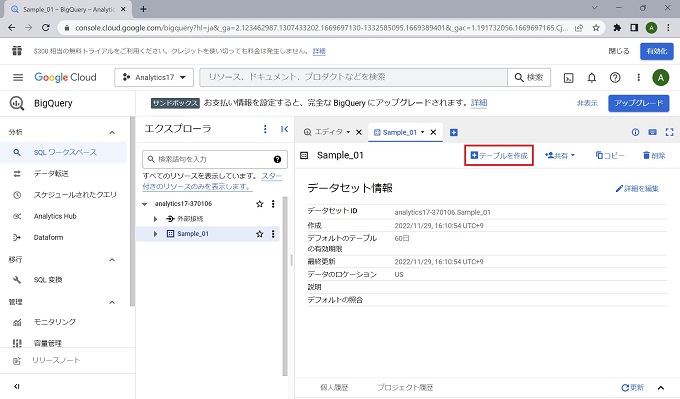
テーブルの作成
前節でデータセットを作成したあとは、いよいよテーブルの作成です。RDBMSでも同様ですが、データセット(データベース)の作成は特に難しいことではありません。
一方、テーブルの作成は実際のデータの格納先になりますので、スキーマの定義など、データベースの知識が問われる工程です。
なお、テーブルの作成は[空のテーブルを作成]、[他のクラウドサービスからの連携]、[アップロード]から選択できますが、当記事ではcsvのアップロードで作成します。
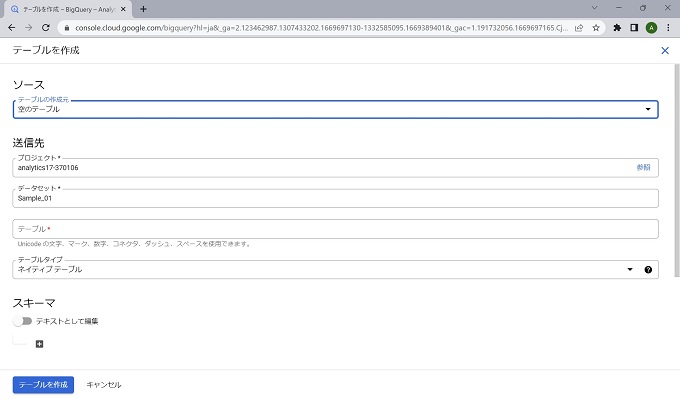
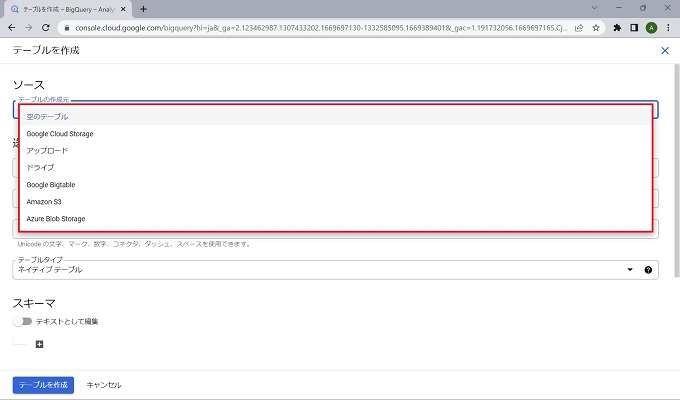
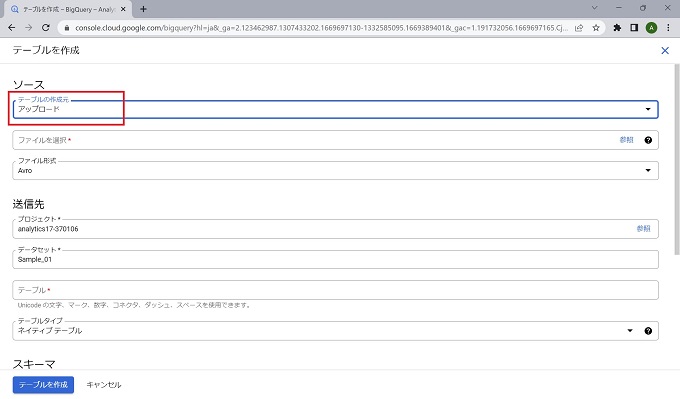
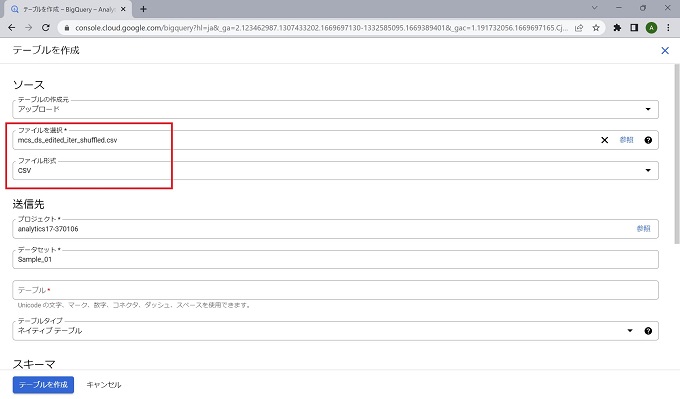
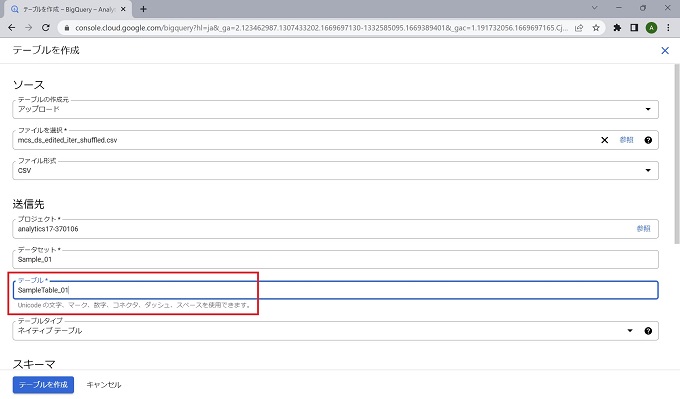
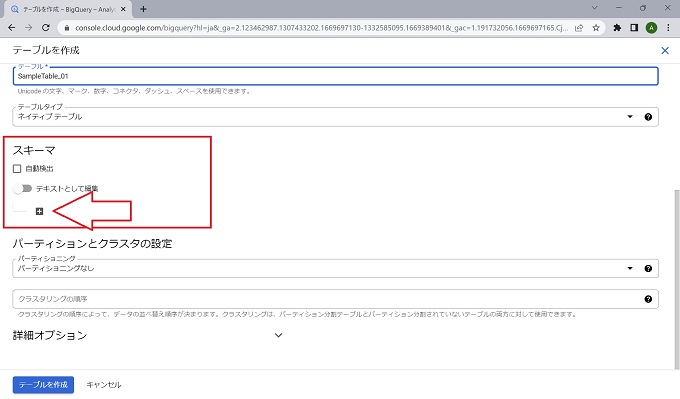
本来、テーブルのスキーマはデータ管理の最重要ともいえる定義のため、手動で正確に定義することが望ましいのですが、当記事では[自動検出]機能を使って進めます。テーブル作成の詳細については、情報量が多いため、別記事で説明します。
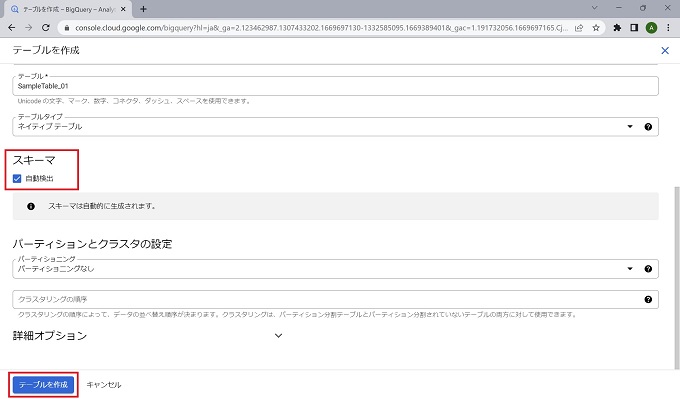
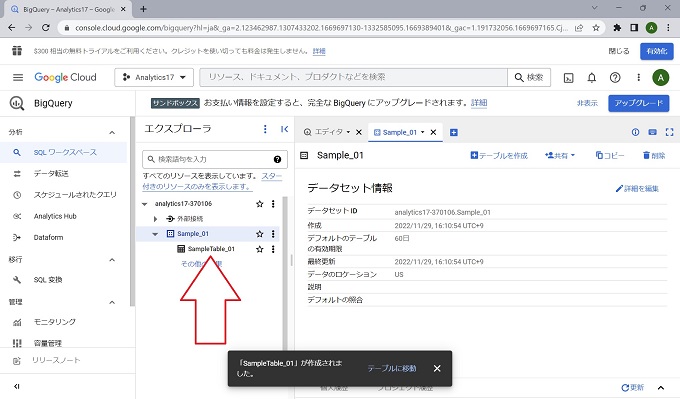
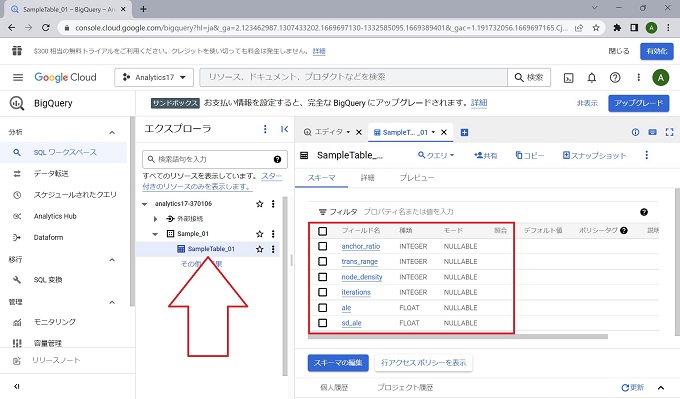
以上、BigQueryのテーブルの作成手順です。この時点で、SQL文を実行できる状態です。
BigQueryでクエリを実行
ここまでに、BigQueryの初期登録からプロジェクト・データセット・テーブルの作成について説明しました。
細かい用途ごとの使い方は、それぞれの記事で説明していきますが、当記事ではBigQueryで簡単なクエリを実行する手順のみ紹介したいと思います。
クエリの実行
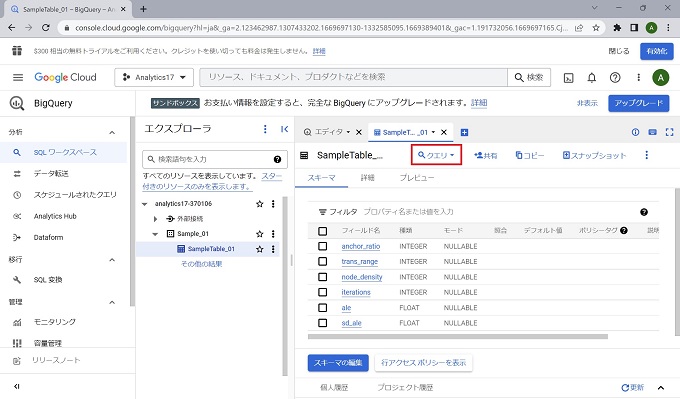
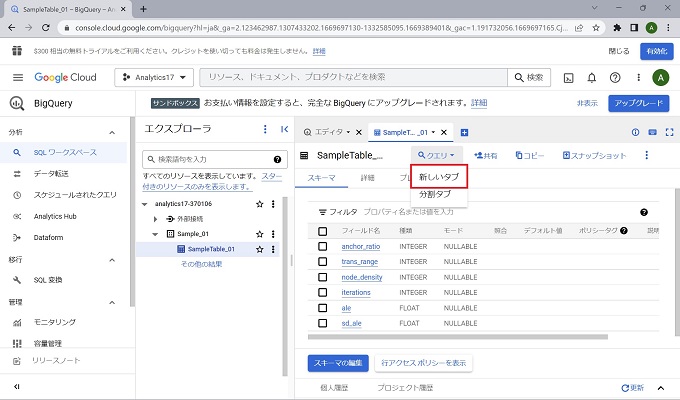
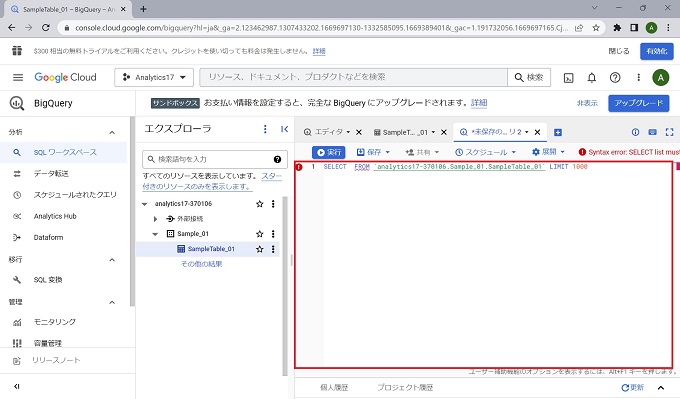
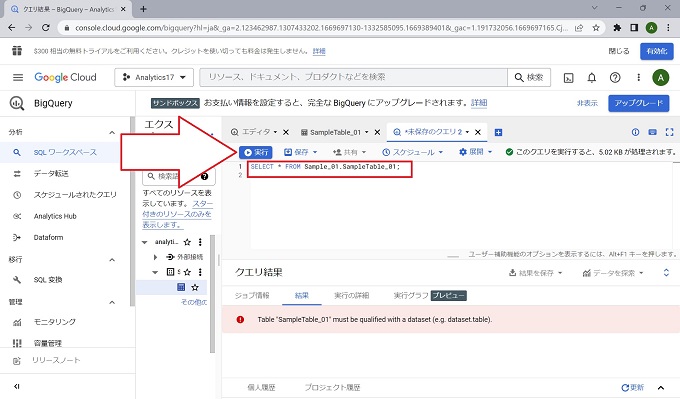
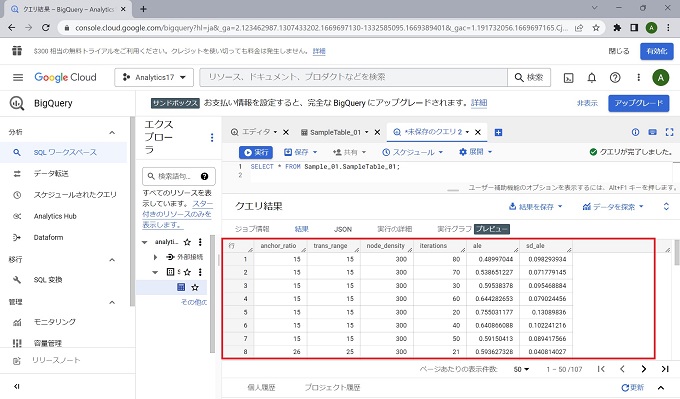
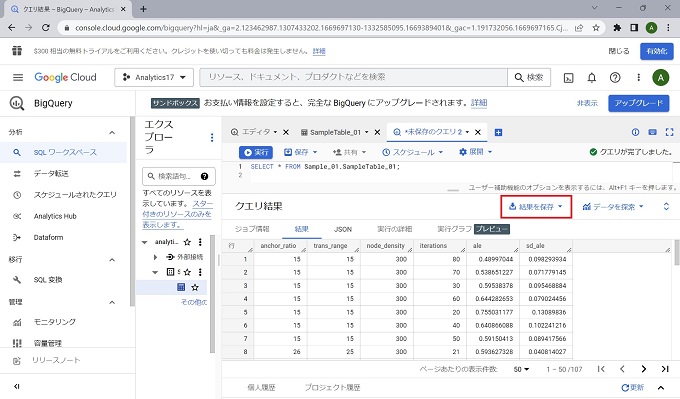
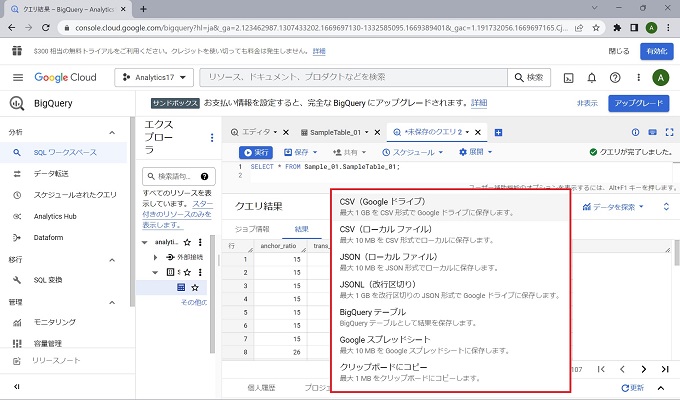
以上、BigQueryのクエリ実行の実画面です。
あとがき
今回は、Googleが提供するデータウェアハウスBigQueryの初期登録から、プロジェクト・データセット・テーブルの作成と、簡単なクエリの実行方法まで記事にしました。
これ以降、SQL言語が使えれば、特に困ることはないと思うのですが、勉強中の方やSQLにお詳しくない方についても、当サイトでは引き続きBigQueryやSQLの情報を発信していきますので、またご覧いただければ幸いです。

SQL言語は、BigQueryの他、MySQLやPostgreSQLでも使える汎用性の高い言語のため、勉強する価値は非常に高いです。