
今回は、SQLの集合演算子のひとつ『UNION(和集合)』について説明します。
UNIONは、集合演算子の中でも最も基本的かつ代表的な集合演算子で、2つの検索結果を足して1つにまとめる動作をします。
この記事では、UNION(和集合)のSQL文の書き方と実例を実際のRDBMSの画像も用いて説明します。
UNION(和集合)のおさらい
UNIONのSQL文や実例を説明する前に、UNIONの概要をおさらいしておきましょう。
UNIONとは
UNIONは、2つの検索結果を足して1つにまとめる場合に使う集合演算子です。

上記のイメージ図で説明します。2つの円は、それぞれ異なるテーブルから抽出された検索結果を表しています。
イメージ図では、左の円、右の円、そして左の円と右の円が重なり合う箇所にも色付けされていますので、UNIONの集合結果には、下記のデータがすべて含まれることを意味しています。
- Aテーブルからの検索結果だけにあるデータ
- Bテーブルからの検索結果にだけあるデータ
- Aテーブル、Bテーブル両方の検索結果にあるデータ
UNIONを使うシーン
UNIONは、2つの検索結果を単純に1つにまとめるときに使います。たとえば、前月分の検索結果と当月分の検索結果を1つの検索結果にまとめたい場合などです。
ただし、集合演算子はあくまでも表を1つにまとめるだけであり、数値等が合算される訳ではありませんので、注意してください。
UNION ALLと重複行
集合演算子の中でも、特にUNIONは重複行との関連性が高いです。
UNIONは、2つの検索結果を足し合わせる集合演算子のため、両方の検索結果に同じデータが存在していた場合など、重複しやすい特性があるのです。
重複の例
検索結果①
- A
- B
- C
検索結果②
- C
- D
- E
UNION実行後(和集合)
- A
- B
- C
- C
- D
- E
UNIONのみの場合
UNIONは、ALLを明示しない限り、2つの検索結果を足し合わせた場合、重複行を1行にまとめる動きをします。
検索結果①
- A
- B
- C
検索結果②
- C
- D
- E
SELECT * FROM First_table UNION SELECT * FROM Second_tabel;UNION実行後(和集合)
- A
- B
- C・・1行にまとめられる
- D
- E
UNION ALLの場合
前節のように、重複行を1行にまとめたくない場合には、SQL文でUNION ALLと記述する必要があります。
検索結果①
- A
- B
- C
検索結果②
- C
- D
- E
SELECT * FROM First_table UNION ALL SELECT * FROM Second_tabel;UNION実行後(和集合)
- A
- B
- C
- C
- D
- E
UNION_SQL文の書き方と実例
この章では、UNIONのSQL文の書き方と実例を紹介します。
使用する検索結果
使用する検索結果は下記の2つです。この2つの検索結果を元にして、SQLのUNIONを実際のRDBMSで実行します。
| id | vege_name | class |
|---|---|---|
| 0001 | えのきだけ | 野菜 |
| 0002 | オレンジ | くだもの |
| 0003 | かぼちゃ | 野菜 |
| 0004 | キウイフルーツ | くだもの |
| 0005 | キャベツ | 野菜 |
| 0006 | きゅうり | 野菜 |
| 0007 | グレープフルーツ | くだもの |
| 0008 | ゴーヤ | 野菜 |
| 0009 | さつま芋 | 野菜 |
| 0010 | サラダ菜 | 野菜 |
| id | vege_name | class |
|---|---|---|
| T001 | ゴーヤ | 野菜 |
| T002 | さつま芋 | 野菜 |
| T003 | サラダ菜 | 野菜 |
| T004 | しめじ | 野菜 |
| T005 | だいこん | 野菜 |
| T006 | トマト | 野菜 |
UNIONのSQL文
UNIONを使う場合の基本文法と実際のSQL文について説明します。
基本文法
–重複を1行にまとめる
SELECT文1 UNION SELECT文2;
–重複を無視する
SELECT文1 UNION ALL SELECT文2;
実際のSQL文
- テーブル1・・Vegetable
- テーブル2・・Vegetable_202212
たとえば、テーブル[Vegetable]と[Vegetable_202212]から、列[vege_name]と[class]を抽出し、それぞれの検索結果をUNIONで1つにまとめる場合には、下記のようにSQL文を記述します。
--重複行を1行にまとめる
SELECT vege_name,class FROM Vegetable UNION SELECT vege_name,class FROM Vegetable_202212;--重複を無視する
SELECT vege_name,class FROM Vegetable UNION ALL SELECT vege_name,class FROM Vegetable_202212;実例_MySQLのUNION
実際のRDBMS、MySQLでUNIONを実行して検索結果を1つにまとめた実画像を紹介します。
UNIONの実行
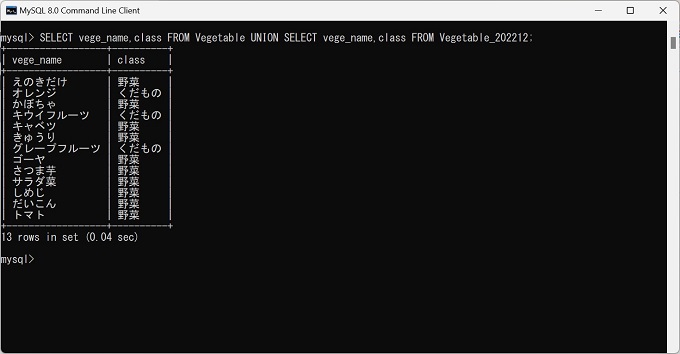
抽出結果:13行(重複は発生していない)
UNION ALLの実行
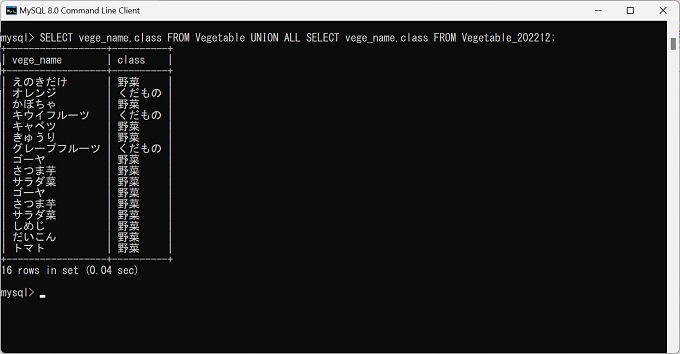
抽出結果:16行(重複が3行発生している)
実例_PostgreSQLのUNION
実際のRDBMS、PostgreSQLでUNIONを実行して検索結果を1つにまとめた実画像を紹介します。
UNIONの実行
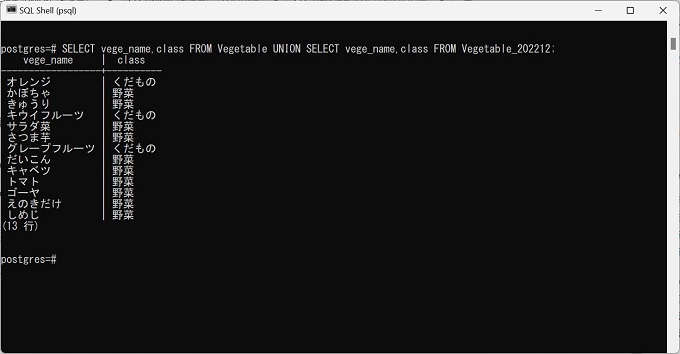
抽出結果:13行(重複は発生していない)
UNION ALLの実行
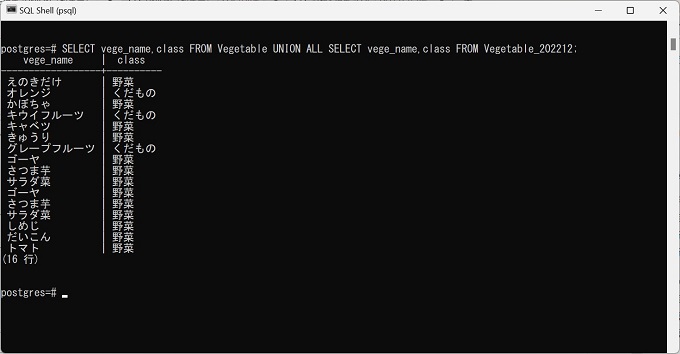
抽出結果:16行(重複が3行発生している)
あとがき
今回は、SQLの集合演算子のひとつ[UNION(和集合)]について、基本的な概要とSQLの書き方、実例を用いた説明を記事にしました。
同じ構造を持つ2つのテーブルの検索結果を1つにまとめる必要がある際に、ぜひ使ってみてください。