
今回は、SQLの集合演算子のひとつ『INTERSECT(積集合)』について説明します。
INTERSECTは、2つの検索結果に含まれている共通部分のみを抽出する動作をします。
この記事では、INTERSECT(積集合)のSQL文の書き方と実例を実際のRDBMSの画像も用いて説明します。
INTERSECT(積集合)のおさらい
INTERSECTのSQL文や実例を説明する前に、INTERSECTの概要をおさらいしておきましょう。
INTERSECTとは
INTERSECTは、2つの検索結果に含まれている共通部分のみを抽出するときに使う集合演算子です。
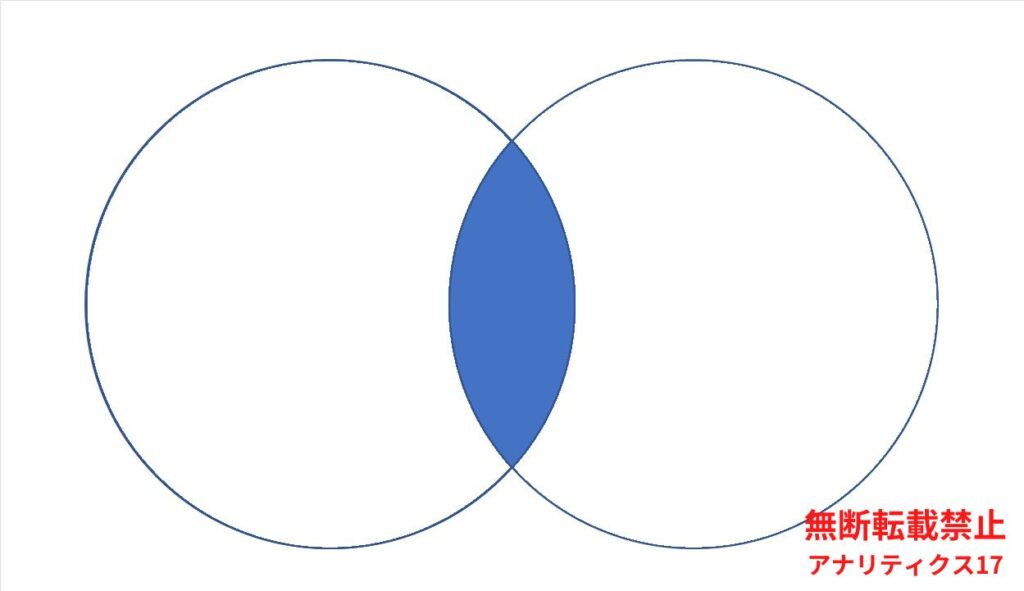
上記のイメージ図で説明します。2つの円は、それぞれ異なるテーブルから抽出された検索結果を表しています。
イメージ図では、左の円と右の円が重なり合う箇所のみ色付けされていますので、INTERSECTの集合結果は、下記のデータのみが含まれることを意味しています。
- Aテーブル、Bテーブル両方の検索結果にある共通データ
INTERSECTを使うシーン
INTERSECTは、2つの検索結果に含まれているデータを抽出したいときに使います。たとえば、前月分の検索結果と当月分の検索結果の両方に存在している費目を抽出したい場合などです。
INTERSECT ALLと重複行
INTERSECTは、2つの検索結果に含まれているデータを抽出する集合演算子ですが、それぞれの検索結果に重複データが含まれている場合、通常はひとつにまとめる動きをします。
ただし、「INTERSECT ALL」と明示することで重複データをすべて抽出することができます。
重複の例
検索結果①
- A
- B
- C
- C
- D
- E
検索結果②
- C
- C
- D
- E
- F
- G
INTERSECT実行後(積集合)
- C
- C
- D
- E
INTERSECTのみの場合
INTERSECTはALLを明示しない限り、2つの検索結果を抽出した場合、重複行を1行にまとめる動きをします。
検索結果①
- A
- B
- C
- C
- D
- E
検索結果②
- C
- C
- D
- E
- F
- G
SELECT * FROM First_table INTERSECT SELECT * FROM Second_tabel;INTERSECT実行後(積集合)
- C・・1行にまとめられる
- D
- E
INTERSECT ALLの場合
前節のように、重複行を1行にまとめたくない場合には、SQL文でINTERSECT ALLと記述する必要があります。
検索結果①
- A
- B
- C
- C
- D
- E
検索結果②
- C
- C
- D
- E
- F
- G
SELECT * FROM First_table INTERSECT ALL SELECT * FROM Second_tabel;INTERSECT実行後(積集合)
- C
- C
- D
- D
- E
- E
INTERSECTの重複の考え方は、それぞれの検索結果にすでに存在しているデータの重複です。検索結果①と検索結果②を集合したことによる重複ではありません。
上記の例では、検索結果①にも検索結果②にも「C」が重複して存在しており、INTERSECTで集合した際、それぞれの「C」をすべて抽出するかどうか、という考え方です。
INTERSECT_SQL文の書き方と実例
この章では、INTERSECTのSQL文の書き方と実例を紹介します。
使用する検索結果
使用する検索結果は下記の2つです。この2つの検索結果を元にして、SQLのINTERSECTを実際のRDBMSで実行します。
| id | vege_name | class |
|---|---|---|
| 0001 | えのきだけ | 野菜 |
| 0002 | オレンジ | くだもの |
| 0003 | かぼちゃ | 野菜 |
| 0004 | キウイフルーツ | くだもの |
| 0005 | キャベツ | 野菜 |
| 0006 | きゅうり | 野菜 |
| 0007 | グレープフルーツ | くだもの |
| 0008 | ゴーヤ | 野菜 |
| 0009 | さつま芋 | 野菜 |
| 0010 | サラダ菜 | 野菜 |
| 0011 | ゴーヤ | 野菜 |
| id | vege_name | class |
|---|---|---|
| T001 | ゴーヤ | 野菜 |
| T002 | さつま芋 | 野菜 |
| T003 | サラダ菜 | 野菜 |
| T004 | しめじ | 野菜 |
| T005 | だいこん | 野菜 |
| T006 | トマト | 野菜 |
| T007 | ゴーヤ | 野菜 |
INTERSECTのSQL文
INTERSECTを使う場合の基本文法と実際のSQL文について説明します。
基本文法
–重複を1行にまとめる
SELECT文1 INTERSECT SELECT文2;
–重複を無視する
SELECT文1 INTERSECT ALL SELECT文2;
実際のSQL文
- テーブル1・・Vegetable
- テーブル2・・Vegetable_202212
たとえば、テーブル[Vegetable]と[Vegetable_202212]から、列[vege_name]と[class]を抽出し、それぞれの検索結果をINTERSECTで1つにまとめる場合には、下記のようにSQL文を記述します。
--重複行を1行にまとめる
SELECT vege_name,class FROM Vegetable INTERSECT SELECT vege_name,class FROM Vegetable_202212;--重複を無視する
SELECT vege_name,class FROM Vegetable INTERSECT ALL SELECT vege_name,class FROM Vegetable_202212;実例_MySQLのINTERSECT
実際のRDBMS、MySQLでINTERSECTを実行して検索結果を1つにまとめた実画像を紹介します。
INTERSECTの実行
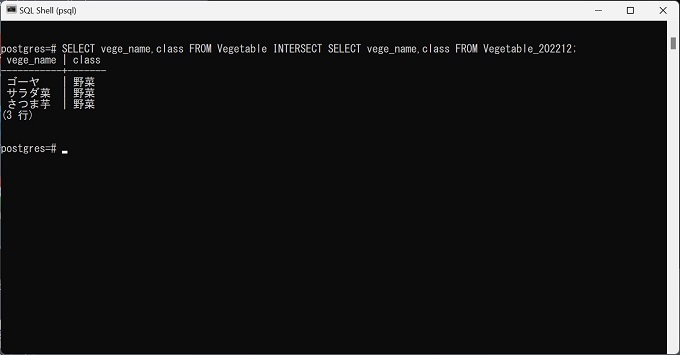
抽出結果:3行(重複は発生していない)
INTERSECT ALLの実行
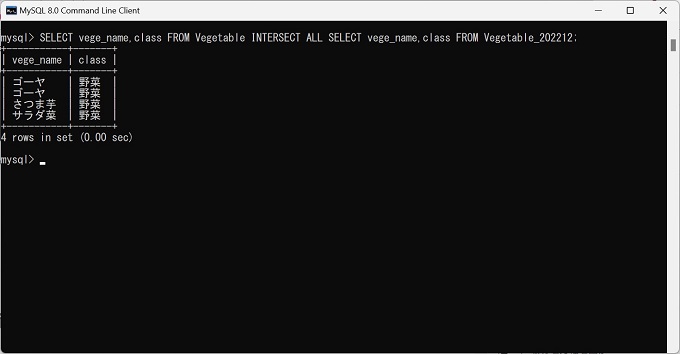
抽出結果:4行(重複が1行発生している)
実例_PostgreSQLのINTERSECT
実際のRDBMS、PostgreSQLでINTERSECTを実行して検索結果を1つにまとめた実画像を紹介します。
INTERSECTの実行
抽出結果:3行(重複は発生していない)
INTERSECT ALLの実行
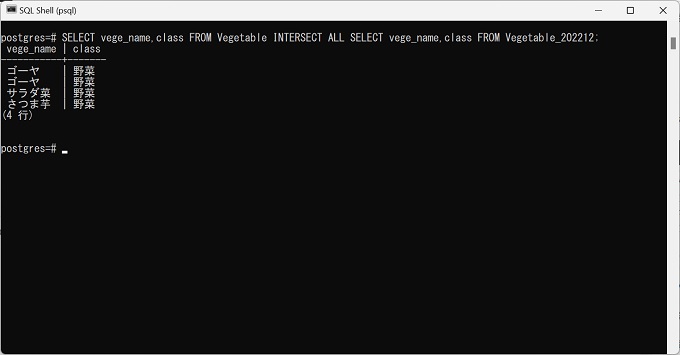
抽出結果:4行(重複が1行発生している)
あとがき
今回は、SQLの集合演算子のひとつ[INTERSECT(積集合)]について、基本的な概念とSQLの書き方、実例を用いた説明を記事にしました。
同じ構造を持つ2つのテーブルから、両方に含まれるデータを抽出する必要がある際に、ぜひ使ってみてください。