
今回は、SQLの大文字と小文字の扱いについて説明します。
一般に「SQLは大文字と小文字を区別しない」という情報をよく見かけますが、正確にはSELECTやFROMなどのSQLキーワード、テーブル名・カラム名で使われる識別子、そしてテーブルに格納されているデータ、それぞれで扱いは異なるはずです。
また、RDBMSにも複数の製品がありますので、一概に大文字と小文字を区別しないと言い切れないかもしれません。
この記事では、SQLの大文字と小文字の区別について、対象SQLと代表的なRDBMSを例にして紹介します。
SQLの大文字と小文字の扱い
次の章より、SQLの大文字と小文字の扱いについて詳細解説します。大文字と小文字を区別するかどうかは、SQLキーワードやテーブル名などの「単語が使われる分類」によって異なります。
また、RDBMSによって挙動の違いもあり、他の多くのソフトウェアと同様に、ユーザー設定機能やデフォルト値も存在します。
なお、大文字や小文字の区別に関する設定機能について、RDBMSでは「照合順序」と表現されます。
SQLキーワード
SELECTやFROM、DELETE、WHEREのようなSQLキーワードについては、ほとんどのRDBMSにおいて、大文字と小文字を区別しません。
つまり、下記のSQL文に対して同じ結果を返します。
SELECT * FROM employees;
select * from employees;INSERT INTO customers (name, age) VALUES ('Alice', 30);
insert into customers (name, age) values ('Alice', 30);文中で「ほとんどのRDBMSにおいて」と説明していますが、現代の主要なRDBMSでSQLキーワードの大文字小文字を区別する製品はありません。ただし、RDBMSでもマイナーな製品や古いバージョンの製品では、存在しているかもしれません。本記事の説明は、その点を考慮した表現となります。
テーブル名・カラム名などの識別子
テーブル名やカラム名で使われる識別子についても、SQLキーワード同様、主要なRDBMSのデフォルト設定では大文字と小文字を区別しません。ただし、製品ごとに細部の相違点はあります。
PostgreSQL
PostgreSQLは、通常の検索では識別子の大文字と小文字を区別しません。ただし、例外的にダブルクォートで囲んだ識別子については大文字と小文字を区別します。
SELECT * FROM TEST_TABLE; ・・区別しない
SELECT * FROM "TEST_TABLE"; ・・区別するMySQL
MySQLは、オペレーティングシステムによって、識別子の大文字と小文字の区別に関するデフォルト値が異なります。
設定値0:Unix/Linuxデフォルト
テーブル名・カラム名の大文字と小文字を区別します。
設定値1:Windowsデフォルト
テーブル名・カラム名の大文字と小文字を区別しません。
設定値2:macOS
テーブル名・カラム名を作成するときには大文字と小文字を区別しますが、参照時には区別しません。
MySQLで下記のコードを実行することで、’lower_case_table_names’の設定値を確認できます。
show variables where variable_name='lower_case_table_names';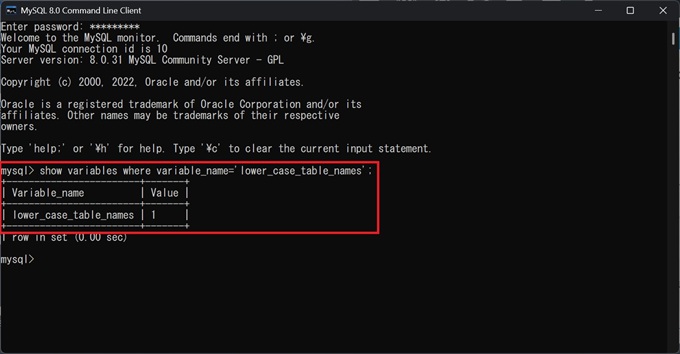
SQL Server
SQL Serverは、「照合順序」の設定値によって、識別子の大文字と小文字の区別に関する扱いが異なります。
設定値:CI (Case Insensitive)
テーブル名・カラム名の大文字と小文字を区別しません。
(h4)設定値:CS (Case Sensitive)
テーブル名・カラム名の大文字と小文字を区別します。
SQL Serverの照合順序は、データベースやカラムごとに設定されています。下記のコードは、指定したデータベースの照合順序を確認するSQLです。
SELECT name, collation_name
FROM sys.databases
WHERE name = 'データベース名';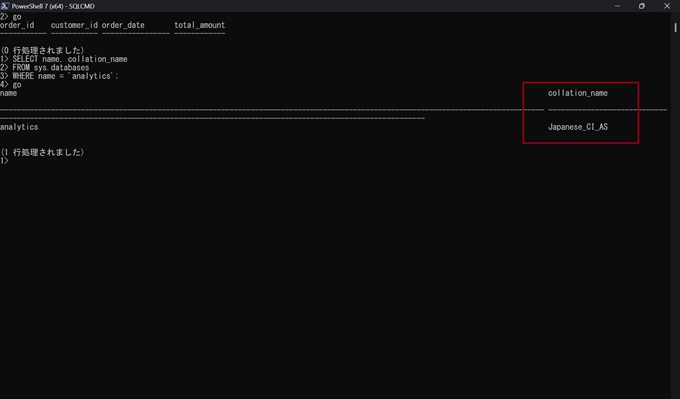
なお、当サイトの環境において、デフォルト値は「CI (Case Insensitive)」であり、大文字小文字を区別しない初期設定になっていますが、照合順序はデータベース作成時に下記のように指定することも可能です。
CREATE DATABASE analytics
COLLATE Japanese_CS_AS;作成後のデータベースの照合順序を変更する場合には、下記のSQLを実行します。
ALTER DATABASE analytics
COLLATE Japanese_CS_AS;データ値(格納データ)
テーブルに格納されているデータについては、RDBMSによって大文字と小文字の区別の扱いが異なります。また、識別子同様、OS環境や照合順序に依存するRDBMSもあります。
PostgreSQL
PostgreSQLは、データ値の大文字と小文字を区別します。つまり、テキストデータを検索する際、大文字と小文字は別の値として認識されます。ただし、LOWER関数を使うことで明示的に大文字と小文字を区別しないで検索することは可能です。
SELECT * FROM products WHERE product_name = 'smartphone'; ・・区別する
SELECT * FROM products WHERE LOWER(product_name) = LOWER('smartphone'); ・・区別しない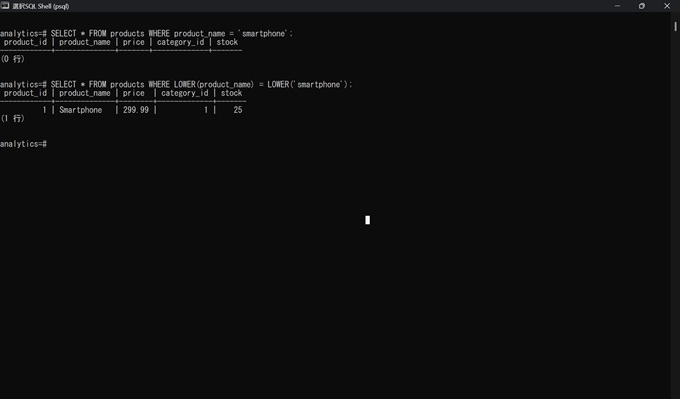
MySQL
MySQLは、「照合順序」の設定値によって、格納データの大文字と小文字の区別に関する扱いが異なります。デフォルトの照合順序では大文字小文字を区別しませんが、明示的に設定することで区別することができます。
設定値:*_ci(Case Insensitive)
格納データの大文字と小文字を区別しません。
設定値:*_cs(Case Sensitive)
格納データの大文字と小文字を区別します。
下記のSQLを実行することで、MySQLで利用可能な照合順序を確認することができます。
SHOW COLLATION;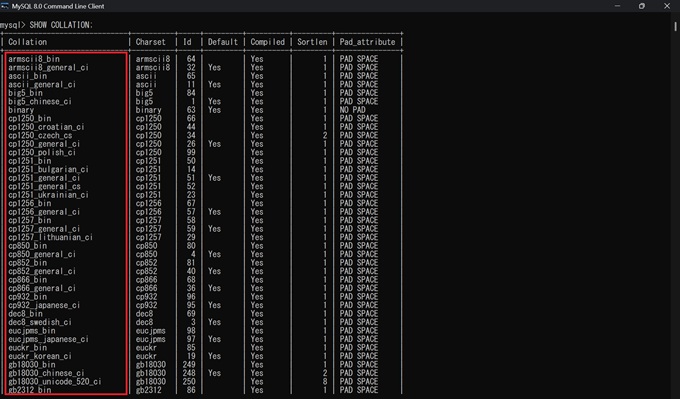
表示される照合順序のうち、末尾のアルファベットが「_ci」であれば格納データの大文字と小文字を区別しません。「_cs」であれば大文字と小文字を区別します。
MySQLでは、データベースやテーブル、カラムごとに照合順序を設定できます。下記のSQLはその一例です。
-- データベースを作成する際の照合順序指定
CREATE DATABASE MyDatabase
CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
-- テーブル作成時にカラムレベルで照合順序を指定
CREATE TABLE MyTable (
id INT,
name VARCHAR(100) COLLATE utf8mb4_bin
);
-- 既存のカラムの照合順序を変更
ALTER TABLE MyTable MODIFY name VARCHAR(100) COLLATE utf8mb4_general_ci;
SQL Server
SQL Serverでは、テーブル名・カラム名の識別子同様、格納データの大文字と小文字の区別に関する扱いも照合順序に依存します。
なお、格納データの大文字小文字区別については、カラム単位に設定することが可能で、下記のようなSQLを実行することで設定できます。
CREATE TABLE ExampleTable (
Column1 VARCHAR(100) COLLATE Latin1_General_CS_AS -- このカラムは大文字小文字を区別
);あとがき
今回は、SQLの大文字と小文字の区別について、SQLキーワードやテーブル・カラム名、格納データ、それぞれの細部の挙動まで踏み込んで解説しました。
当サイトの記事で扱っているPostgreSQLやMySQL、SQL Serverは世界的に使われるRDBMSであり、世界の言語が持つ多様な文化的ニーズに対応するために、細やかな設定(照合順序)が可能になっているのです。
そのため、「SQLは大文字・小文字を区別しない」のような明快かつ単純な結論はなく、どのような構造で動いているのかを理解することが正確な知識に繋がるのです。