
この記事では、SQLのSELECT DISTINCTを使って、重複データを除外してデータを抽出する方法を説明します。また、MySQLやPostgreSQLでSELECT DISTINCTを実行した際の実画像も紹介します。
SQL_重複データを除外してデータを抽出(SELECT DISTINCT)
この章では、RDBMSに登録されているテーブルから、SELECT DISTINCT文を使って重複データを除外して抽出する方法を説明します。
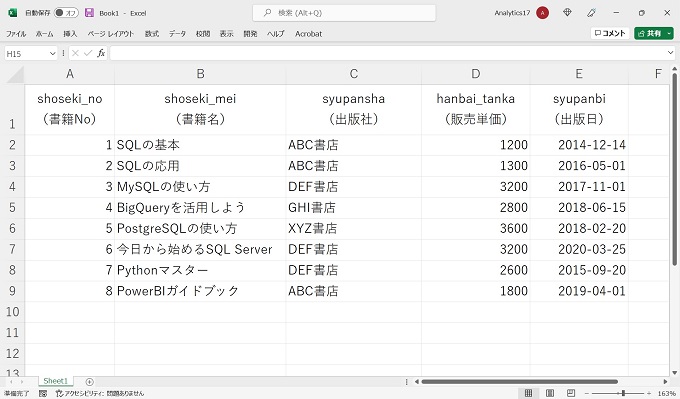
テーブルのデータは下記の通りです(ここでは、便宜上、Excel形式にしています)。
このテーブルの[syupansha]の列のデータを重複を除外して抽出します。

基本のSELECT DISTINCT文
テーブルから重複を除外してデータを抽出するときには、[SELECT DISTINCT]というSQL文を実行します。
下記のように、SELECTと列名の間に[DISTINCT]を記述します。
基本文法
–1列のみを抽出する
SELECT DISTINCT 列名 FROM テーブル名;
–複数列を抽出する
SELECT DISTINCT 列名1,列名2 FROM テーブル名;
実際のSELECT DISTINCT文
下記のテーブルから、[syupansha]列の情報を抽出してみます。
SQL[SELECT文]
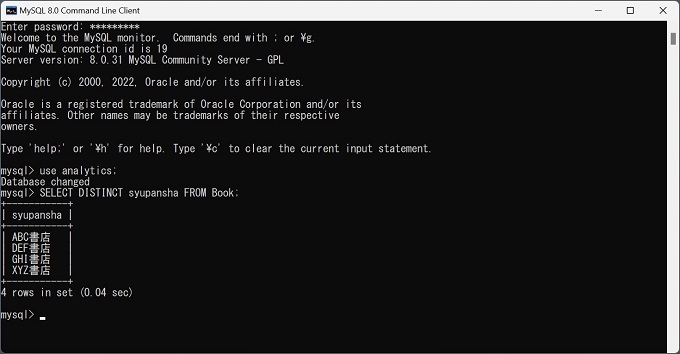
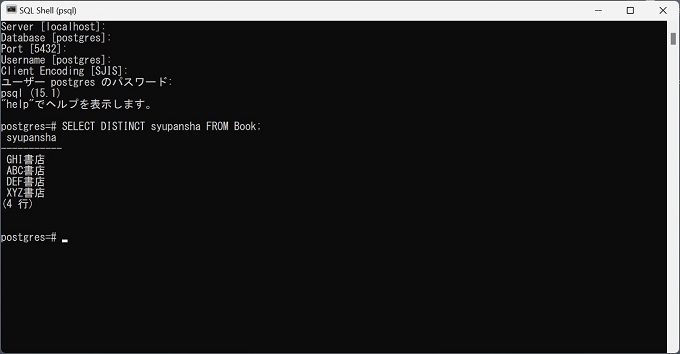
SELECT DISTINCT syupansha FROM Book;実行結果
syupansha
ABC書店
DEF書店
GHI書店
xyz書店複数列を抽出するSELECT DISTINCT文
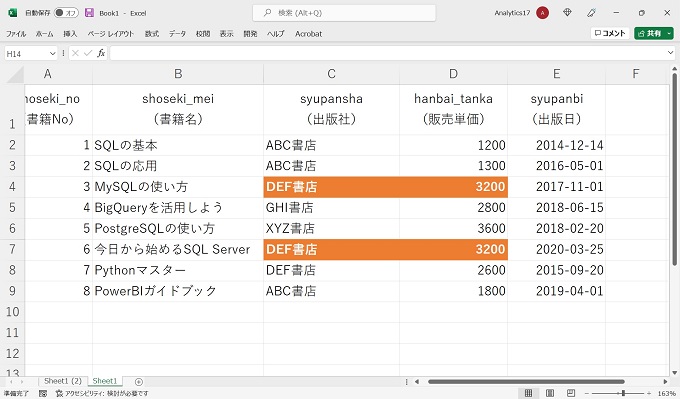
次に、重複を除外してデータを抽出する列を[syupansha][hanbai_tanka]の2列に拡大してみます。
なお、[syupansha]の列と[hanbai_tanka]の列、2列分を組み合わせても重複しているのは、下記の2レコードのみです。
SQL[SELECT文]
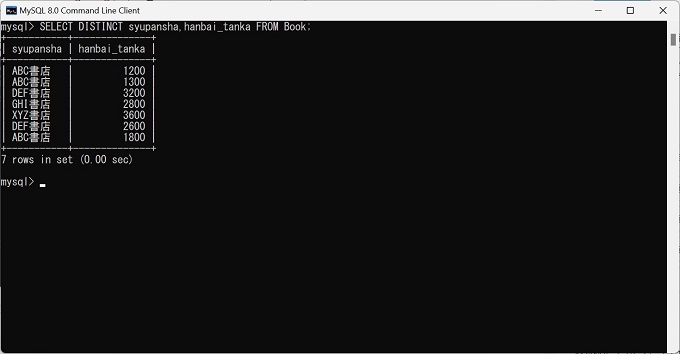
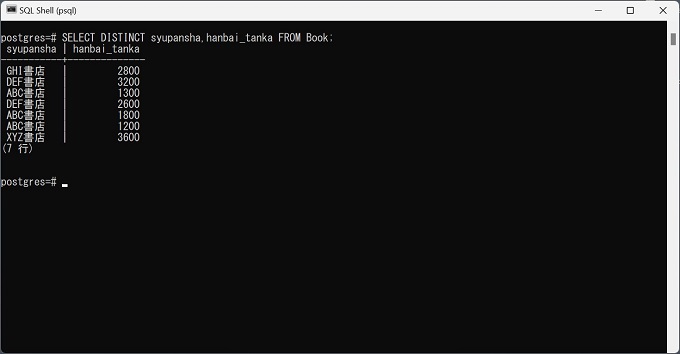
SELECT DISTINCT syupansha,hanbai_tanka FROM Worker;実行結果
syupansha hanbai_tanka
ABC書店 1200
ABC書店 1300
DEF書店 3200
GHI書店 2800
xyz書店 3600
DEF書店 2600
ABC書店 1800DISTINCTは、SQL文の先頭の列名の前にしか記述できません。そのため、重複データの除外が複数列に跨る場合でも、必ず先頭の列名の前に記述します。
SELECT DISTINCT syupansha,hanbai_tanka FROM Worker;これは「抽出対象の複数列の中から、2列目のみ重複データを除外する」等という指定は、論理的に成り立たないためです。
実例_MySQLのSELECT DISTINCT
実際のRDBMS、MySQLでSELECT DISTINCT文を実行してテーブルから重複データを除外したデータを抽出した実画像を紹介します。
1列のみを抽出(SELECT DISTINCT)
2列を抽出(SELECT DISTINCT)
実例_PostgreSQLのSELECT DISTINCT
実際のRDBMS、PostgreSQLでSELECT DISTINCT文を実行してテーブルから重複データを除外したデータを抽出した実画像を紹介します。
1列のみを抽出(SELECT DISTINCT)
2列を抽出(SELECT DISTINCT)
あとがき
今回は、SELECT DISTINCT文を使って重複データを除外したデータを抽出する方法について、記事にしました。
RDBMSからのデータ抽出は、SELECT単体で実行される機会は少なく、今回のように重複を削除したり、条件に合致したデータのみに限定したりと、加工をして抽出することがほとんどです。
引き続き、当サイトではSQL関連の記事を発信していきますので、またご覧ください。