
平均値が同じデータでも、値が中心の近くにまとまっているか、広く散らばっているかで意味はまったく変わります。
この「ばらつきの大きさ」を数値で表すのが分散と標準偏差です。両者は計算の途中と完成形の関係にあり、分散の平方根が標準偏差です。
本稿では、分散と標準偏差の違い、手計算の手順、標本と母集団で割る数が変わる理由、そして SQL・BigQuery・Excel での求め方を、製品ごとの関数差まで含めて整理します。
この記事で分かること
- 分散と標準偏差がそれぞれ何を表し、なぜ 2 つに分かれているのか
- 偏差 → 分散 → 標準偏差という計算の流れと手計算の手順
- 「n で割る」か「n−1 で割る」か(母集団と標本)の違いと選び方
- SQL・BigQuery・Excel での計算方法と、製品ごとの関数名・既定値の差
分散と標準偏差は何が違うのか
分散も標準偏差も「データが平均値からどれくらい散らばっているか」を表す指標です。違いは単位にあります。
| 指標 | 定義 | 単位 | ひとことで言うと |
|---|---|---|---|
| 分散(variance) | 各データの「平均との差」を二乗した値の平均 | 元データの単位の二乗 | ばらつきを二乗で測った中間量 |
| 標準偏差(standard deviation) | 分散の正の平方根 | 元データと同じ単位 | ばらつきを元の単位に戻した値 |
分散は計算の過程で差を二乗するため、たとえばデータが「点」なら分散の単位は「点²」になり、元の値と直接比べられません。そこで平方根をとって単位を「点」に戻したものが標準偏差です。解釈や他の値との比較には標準偏差を使い、分散はその計算の途中段階かつ理論的な計算で扱いやすい量、という関係で覚えると整理しやすくなります。
なぜ差をそのまま平均せず二乗するのかというと、平均との差(偏差)は正と負が混ざり、単純に合計すると必ず 0 になってしまうためです。二乗して符号をなくしてから平均することで、散らばりの大きさだけを取り出せます。
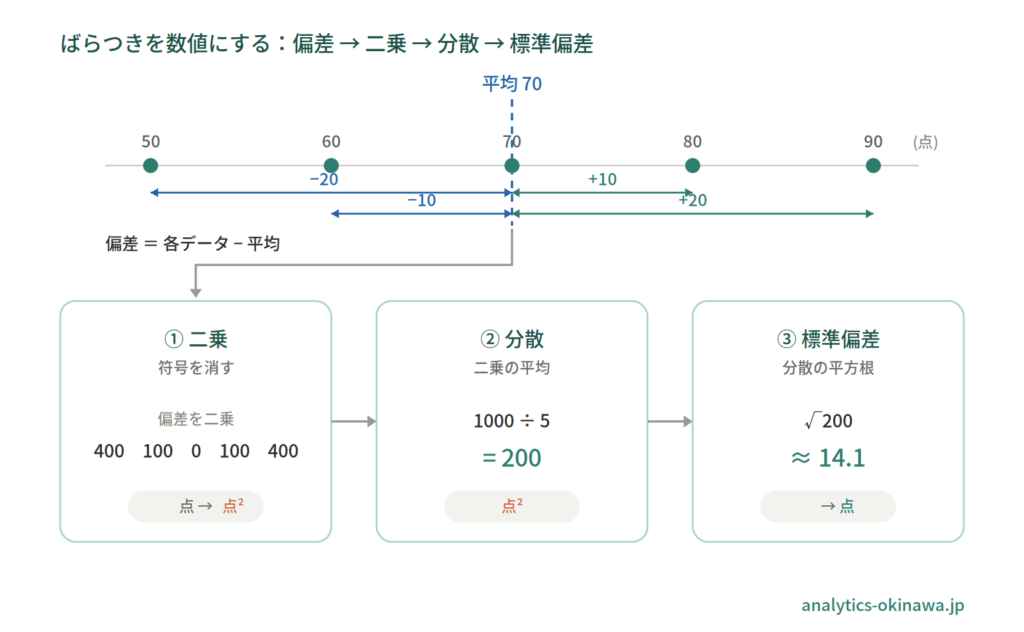
計算方法:偏差から標準偏差まで
分散と標準偏差は、次の 4 ステップで求めます。テストの点数 {50, 60, 70, 80, 90}(5 人分)を例にします。
- 平均値を求める:(50 + 60 + 70 + 80 + 90) ÷ 5 = 70(点)
- 偏差を求める(各データ − 平均):−20, −10, 0, 10, 20
- 偏差を二乗して合計する:400 + 100 + 0 + 100 + 400 = 1000
- 件数で割って平方根をとる:1000 ÷ 5 = 200 が分散、√200 ≈ 14.1 が標準偏差
このデータの分散は 200(点²)、標準偏差は約 14.1 点です。標準偏差が「点」という元の単位に戻っているため、「平均 70 点を中心におよそ ±14 点の幅で散らばっている」と直感的に読めます。
補足:上の手順 4 で「5(件数 n)で割る」のは母集団として扱う場合です。手元の 5 人を、より大きな集団から取り出した標本とみなす場合は「n−1=4 で割る」ため、分散は 250、標準偏差は約 15.8 点になります。この違いは次節で説明します。
標本と母集団:nで割るかn−1で割るか
分散・標準偏差には「割る数」が 2 通りあり、ここが最もつまずきやすいポイントです。
| 区分 | 割る数 | 何を求めているか |
|---|---|---|
| 母分散・母標準偏差 | n(件数そのもの) | 手元のデータ全体そのもののばらつき |
| 標本分散・標本標準偏差 | n−1 | 標本から母集団のばらつきを推定する |
手元のデータが「対象のすべて(母集団)」なら n で割ります。たとえば「あるクラス 30 人全員の点数」のばらつきそのものを知りたい場合です。
一方、手元のデータが「より大きな集団から抜き出した一部(標本)」で、そこから母集団のばらつきを推定したい場合は n−1 で割ります。標本から計算した偏差は母平均ではなく標本平均を基準にするため、ばらつきをやや小さく見積もる癖があり、n−1 で割ることでこの偏りを補正します(ベッセルの補正)。
n−1 で割って求めるこの分散を不偏分散と呼びます(ただし、その平方根である標本標準偏差は厳密には不偏推定量ではない点に注意します)。
どちらを使うかは「目的」で選びます。観測したデータから背後にある母集団のばらつきを推定したいなら標本版(n−1)が、Web ログや売上ログのように手元の全件データそのもののばらつきを記述したいなら母集団版(n)が自然です。
どちらか一方が常に正しいわけではなく、分析の目的で決めます。なお、後述するように製品の関数によって省略形の既定がどちらかは異なるため、関数名で必ず確認してください。n が十分大きいと n と n−1 の差は小さくなり、結果はほとんど変わりません。
SQL・BigQuery・Excelで分散・標準偏差を求める
分散・標準偏差は、集計クエリや表計算関数で直接計算できます。最大の注意点は、関数が「母集団版(POP / P)」と「標本版(SAMP / S)」に分かれていること、そして関数名を省略したときの既定がどちらになるかが製品ごとに違うことです。
SQL(PostgreSQL)
PostgreSQL には、母集団版・標本版の両方がそろっています。
-- PostgreSQL:分散・標準偏差(母集団版と標本版)
SELECT
VAR_POP(score) AS var_pop, -- 母分散(nで割る)
VAR_SAMP(score) AS var_samp, -- 標本分散(n-1で割る)
STDDEV_POP(score) AS stddev_pop, -- 母標準偏差
STDDEV_SAMP(score) AS stddev_samp -- 標本標準偏差
FROM scores;PostgreSQL では、別名の VARIANCE() は VAR_SAMP()、STDDEV() は STDDEV_SAMP() と同じく標本版を指します。省略形を使うと標本版になる点に注意してください。
SQL(製品差)
分散・標準偏差は関数名と既定値の方言差が大きい領域です。標準 SQL の VAR_POP / VAR_SAMP / STDDEV_POP / STDDEV_SAMP をそろえている製品が多い一方、省略形の意味や SQL Server の命名は異なります。
| 区分 | PostgreSQL | MySQL | SQL Server |
|---|---|---|---|
| 母分散 | VAR_POP() | VAR_POP() | VARP() |
| 標本分散 | VAR_SAMP() | VAR_SAMP() | VAR() |
| 母標準偏差 | STDDEV_POP() | STDDEV_POP() | STDEVP() |
| 標本標準偏差 | STDDEV_SAMP() | STDDEV_SAMP() | STDEV() |
| 省略形の既定 | STDDEV()/VARIANCE()=標本 | STDDEV()/STD()/VARIANCE()=母集団 | 省略形なし(STDEV=標本、STDEVP=母集団) |
特に注意したいのが省略形です。MySQL の STDDEV() / STD() / VARIANCE() は母集団版を返すのに対し、PostgreSQL の STDDEV() / VARIANCE() は標本版を返します。
同じ STDDEV() でも製品によって割る数が違うため、どちらの定義が必要かを明示し、可能なら _POP / _SAMP を付けた明示的な関数名で書くのが安全です。
SQL Server には _POP / _SAMP という命名がなく、STDEV(標本)/ STDEVP(母集団)、VAR(標本)/ VARP(母集団)を使います。
BigQuery
BigQuery も母集団版・標本版の両方を備えています。
-- BigQuery:分散・標準偏差(母集団版と標本版)
SELECT
VAR_POP(score) AS var_pop,
VAR_SAMP(score) AS var_samp,
STDDEV_POP(score) AS stddev_pop,
STDDEV_SAMP(score) AS stddev_samp
FROM `project.dataset.scores`;BigQuery でも省略形の STDDEV() は STDDEV_SAMP()、VARIANCE() は VAR_SAMP() と同じく標本版です(PostgreSQL と同じ挙動)。
これらは厳密計算の集計関数で、近似版(APPROX_*)とは別物です。分散・標準偏差は通常この VAR_* / STDDEV_* で計算します。ただし BigQuery はクエリがスキャンした列のデータ量に応じて課金されるため、対象の列・期間・WHERE 条件を絞ってスキャン量を抑えるのが実務上の基本です。
SELECT * のように不要な列まで読む書き方は避け、必要な列だけを対象にします。
Excel
Excel は関数名の末尾で母集団版・標本版を区別します。
| 区分 | Excel 関数 | 割る数 |
|---|---|---|
| 標本分散 | =VAR.S(範囲) | n−1 |
| 母分散 | =VAR.P(範囲) | n |
| 標本標準偏差 | =STDEV.S(範囲) | n−1 |
| 母標準偏差 | =STDEV.P(範囲) | n |
.S が標本(sample、n−1)、.P が母集団(population、n)です。先のテスト点数の例なら、=STDEV.P は約 14.1、=STDEV.S は約 15.8 を返します。
注意:旧バージョンの VAR(=標本)・VARP(=母集団)・STDEV(=標本)・STDEVP(=母集団)も互換のため残っていますが、現在は .S / .P 付きの関数が推奨されます。SQL Server の VAR / VARP とは名前が同じでも意味の対応が異なるため、製品をまたぐときは取り違えに注意してください。
注意点
「分散」「標準偏差」だけでは母集団版か標本版か決まりません。 同じデータでも n で割るか n−1 で割るかで値が変わります。数値を報告するときは、どちらで計算したか(使った関数名)を添えると誤解を避けられます。
標準偏差は外れ値の影響を強く受けます。 偏差を二乗してから平均するため、平均から大きく離れた 1 件が結果を大きく押し上げます。外れ値が疑われるデータでは、標準偏差だけでばらつきを語らず、中央値や四分位範囲などの指標も併せて確認します。
外れ値そのものの扱いは別記事を参照してください。
単位や桁が違うデータ同士は、標準偏差を直接比べられません。 「売上(円)の標準偏差」と「PV(回)の標準偏差」を大小比較しても意味がありません。ばらつきの相対的な大きさを比べたいときは、標準偏差を平均値で割った変動係数(CV)などを使います。
欠損値(NULL・空白)は計算から除外されます。 SQL の集計関数は通常 NULL を無視して計算し、Excel でも空白セルは計算対象に含まれません。
そのため欠損が多いデータでは、実際に計算へ使われた件数が想定より少なくなり、標準偏差が不安定になったり、母集団のつもりが一部だけの値になっていたりします。標準偏差を求める前に、全体件数と NULL(空白)件数を確認し、「何件で計算したのか」を把握しておきます(SQL なら COUNT(*) と COUNT(列) の差で NULL 件数が分かります)。
標準偏差の解釈は分布の形に依存します。 「平均 ±1 標準偏差におよそ 68% が入る」という目安は正規分布を前提とした近似で、歪んだ分布では当てはまりません。
標準偏差と分布の形を結びつける考え方は別記事「正規分布とはなにか|標準化と基本的な考え方」で扱います。
まとめ
分散はデータのばらつきを「偏差の二乗の平均」で表した値、標準偏差はその平方根で、元データと同じ単位に戻したものです。
解釈には単位のそろう標準偏差を使い、分散はその計算の途中段階と位置づけると整理できます。計算は「偏差 → 二乗 → 平均(分散)→ 平方根(標準偏差)」の流れで、手元のデータを母集団として扱うなら n で、標本として母集団を推定するなら n−1 で割ります。
SQL・BigQuery・Excel のいずれにも母集団版・標本版の関数があり、特に省略形(STDDEV など)の既定が MySQL では母集団、PostgreSQL・BigQuery では標本と分かれる点に注意が必要です。どの定義で計算したかを明示することが、ばらつきを正しく伝える第一歩になります。