
手元のデータを一言で表す「代表値」には、平均値・中央値・最頻値の3つがあります。
どれも「データの中心」を指す数値ですが、分布が歪んでいたり外れ値が混ざっていたりすると、3つは別々の値を返し、どれを選ぶかで結論が変わります。本稿では、3つの代表値の定義と計算方法、外れ値や分布の形に応じた使い分けの判断軸、そしてSQL・BigQuery・Excelでの求め方を整理します。
この記事で分かること
- 平均値・中央値・最頻値それぞれが「データの中心」をどう定義しているか
- 3つが一致するとき・大きくずれるとき、その背後で分布に何が起きているか
- 外れ値や歪んだ分布のとき、どの代表値を選べば誤読を避けられるか
- SQL・BigQuery・Excelで3つの代表値をどう計算するか(製品差を含む)
平均値・中央値・最頻値は何が違うのか
代表値は「データがどのあたりに集まっているか(中心)」を1つの数値で表したものです。3つの違いは、何をもって「中心」とするかの定義にあります。
| 代表値 | 定義 | ひとことで言うと |
|---|---|---|
| 平均値(mean) | 全データの合計をデータ件数で割った値 | 値の大きさを平らに均した点 |
| 中央値(median) | データを小さい順に並べたときの真ん中の値 | 順位がちょうど中央の点 |
| 最頻値(mode) | 最も多く出現する値 | いちばん「よくある」値 |
たとえば購入金額が {800, 1000, 1200, 1200, 30000} の5件なら、平均値は6,840円、中央値は1,200円、最頻値は1,200円です。30,000円という1件の高額購入によって平均値だけが大きく跳ね上がり、中央値・最頻値とは別の値になっています。この「ずれ」こそが代表値を使い分ける理由です。
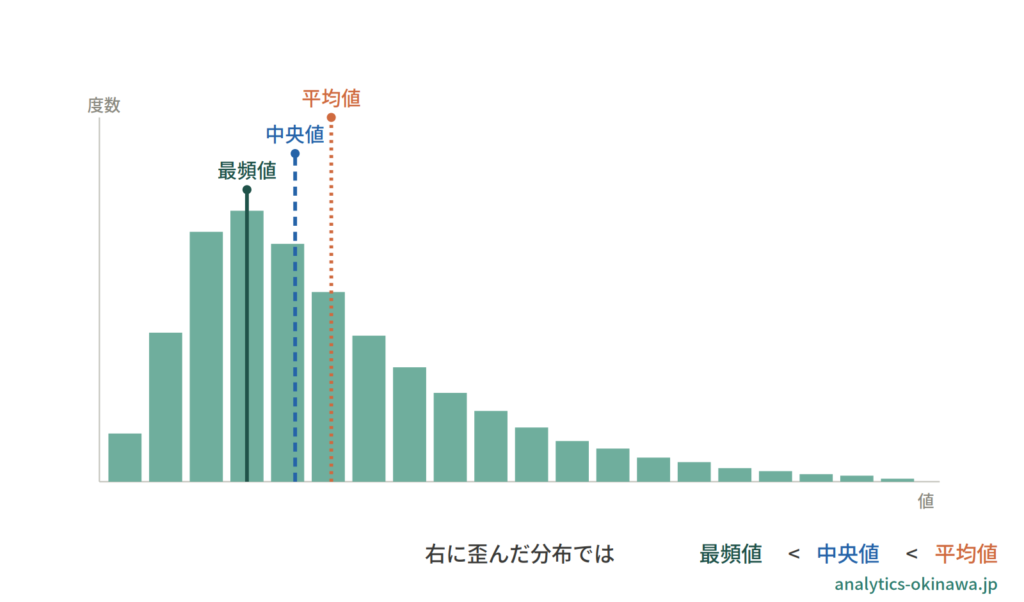
使い分けの判断軸
3つのどれを使うかは、おもに「分布の形」と「外れ値の有無」で見当をつけます。判断の出発点になるのが平均値と中央値の比較です。
両者が近ければ分布はおおむね対称、大きく離れていれば分布が歪んでいる可能性が高い——という目安として、まずこの差を確認します(最終的にはヒストグラムで形を確かめます)。
外れ値が疑われるときは中央値が目安
平均値は全データの合計を使うため、極端に大きい(小さい)値が1つあるだけで引っ張られます。先の例で30,000円が平均を押し上げたのがこれです。中央値は順位の真ん中だけを見るので、端の値がどれだけ極端でも動きにくく、外れ値の影響を受けにくい指標です。
そのため、年収・購入金額・滞在時間・不動産価格のように一部の大きな値が裾を引きやすいデータでは、「平均」より中央値のほうが「典型的な水準」を素直に表しやすくなります。世帯年収で平均より中央値が併記されることが多いのはこのためです。外れ値そのものの検出と扱いは別記事「外れ値とはなにか」で扱います。
左右対称で外れ値が少ないなら平均値
身長・テストの素点・測定誤差のように、分布が概ね左右対称で極端な値が少ない場合は、平均値が最も情報量の多い代表値です。
平均値は全データの値を計算に使うため、後続の分散・標準偏差の計算とも地続きで、統計処理との相性が良いという利点があります。標準偏差との関係は別記事「分散と標準偏差の違いと計算方法」を参照してください。
カテゴリや離散値なら最頻値
平均値や中央値は数値の大小に意味があるデータ(量的データ)でしか使えません。
「最も売れたサイズはM」「最も多い問い合わせ区分は返品」のように、順序や四則演算が意味をなさないカテゴリデータ(質的データ)で「いちばん多いもの」を表せるのは最頻値だけです。
また、アンケートの5段階評価のような離散値で「最も回答が集中した選択肢」を見たいときにも最頻値が向きます。
判断軸のまとめ
| 状況 | 目安となる代表値 | 理由 |
|---|---|---|
| 外れ値が疑われる/分布が歪んでいる | 中央値 | 極端な値に引っ張られにくい |
| 左右対称で外れ値が少ない | 平均値 | 全データを使い情報量が多い |
| カテゴリ・名義データ | 最頻値 | 大小のない値でも「最多」を表せる |
| 分布の山が複数ある(多峰性) | (単一の代表値では不十分) | ヒストグラムで形を確認する |
実務では「まず平均値と中央値を併記し、両者のずれで分布の歪みを察知する」のが定石です。
両者が離れていたらヒストグラムで分布の形を確認します。ヒストグラムの読み方は別記事を参照してください。
SQL・BigQuery・Excelで代表値を求める
3つの代表値は、日常の集計クエリや表計算関数でそのまま計算できます。ただし、平均値が共通して簡単なのに対し、中央値・最頻値は製品ごとに対応状況が分かれるため注意が必要です。
SQL(PostgreSQL)
PostgreSQLでは、平均値はAVG()、中央値・最頻値は順序集合集約関数で求められます。
PostgreSQL — 平均値・中央値・最頻値を1クエリで
SELECT
AVG(amount) AS mean, -- 平均値
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY amount) AS median, -- 中央値
MODE() WITHIN GROUP (ORDER BY amount) AS mode_val -- 最頻値
FROM purchases;PERCENTILE_CONT(0.5)は補間を含む連続版の中央値、MODE()は最頻値を返す順序集合集約関数で、いずれもPostgreSQL 9.4以降で利用できます。
SQLでの中央値の詳しい求め方は別記事で扱います。
SQL(製品差)
中央値・最頻値は方言差が大きい領域です。標準SQLに「MEDIAN」や「MODE」という共通関数はなく、製品ごとに書き方が異なります。
| 代表値 | PostgreSQL | MySQL | SQL Server |
|---|---|---|---|
| 平均値 | AVG() | AVG() | AVG() |
| 中央値 | PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY x) | 専用関数なし(ウィンドウ関数で代替) | PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY x) OVER ()(ウィンドウ関数) |
| 最頻値 | MODE() WITHIN GROUP (ORDER BY x) | 専用関数なし(GROUP BY+件数順で代替) | 専用関数なし(GROUP BY+件数順で代替) |
専用関数がない場合の最頻値は、値ごとに件数を数えて最多の値を1件取る、という汎用的な書き方で代替できます。
SQL — 専用のMODE関数がない環境での最頻値
-- 最多の値を1件取得
SELECT amount AS mode_val
FROM purchases
GROUP BY amount
ORDER BY COUNT(*) DESC
LIMIT 1; -- SQL ServerではLIMITの代わりにSELECT TOP 1同数で並ぶ最頻値が複数あるとき、この書き方はそのうち1件だけを返します。SQL ServerはLIMIT非対応でSELECT TOP 1を使うなど、最終的な構文は使用する製品で検証してください。
BigQuery
BigQueryには集約関数としてのMEDIAN / MODEがありません。中央値は近似分位関数APPROX_QUANTILESで、最頻値はGROUP BY+件数順で求めるのが基本です。
BigQuery — 平均値と中央値(近似)
SELECT
AVG(amount) AS mean,
APPROX_QUANTILES(amount, 100)[OFFSET(50)] AS median_approx
FROM purchases;APPROX_QUANTILES(amount, 100)[OFFSET(50)]は100分割した分位点の50番目、すなわち中央値の近似値です。
厳密な中央値が必要なら、BigQueryではPERCENTILE_CONT(amount, 0.5) OVER ()のようにウィンドウ関数として書きます(BigQueryのPERCENTILE_CONTは引数に値の式と分位点をとる構文で、WITHIN GROUPは使いません)。
ただし大規模テーブルでは計算コストが高くなります。近似と厳密のどちらを使ったかは、結果を報告する際に明示しておくと誤解を避けられます。
Excel
Excelは関数が一対一で対応し、最も手軽です。
| 代表値 | Excel関数 |
|---|---|
| 平均値 | =AVERAGE(範囲) |
| 中央値 | =MEDIAN(範囲) |
| 最頻値 | =MODE.SNGL(範囲) |
MODE.SNGLは最頻値を1つだけ返します。最頻値が複数ある場合にすべて取得したいときはMODE.MULT(配列数式)を使います。
ただし、MODE.SNGL / MODE.MULTは数値専用で、「サイズ=M」「区分=返品」のような文字列カテゴリの最頻値には使えません(文字列を渡すとエラーや#N/Aになります)。カテゴリデータで「いちばん多い値」を求めるときは、次のいずれかで件数を数えて最多のものを選びます。
- ピボットテーブル:対象カテゴリを行に、同じ列を「値(個数 / COUNT)」に置き、件数の降順に並べ替えて最上位を見る
COUNTIF+UNIQUE:UNIQUEでカテゴリの一覧を出し、各値の件数をCOUNTIFで数え、件数が最大の値を取る
なお、ピボットテーブルには中央値・最頻値そのものの集計オプションはないため、数値の中央値・最頻値はMEDIAN / MODE.SNGL関数で別途求めます。
注意点
平均値は「典型的な値」とは限りません。 右に裾を引いた分布では、平均値は実際の多数派より高く出ます。「平均購入額6,840円」は、5人中4人が1,200円以下というこの例の実態を表していません。代表値を1つだけ載せるときは、その分布で妥当かを必ず確認します。
最頻値は連続値では不安定です。 金額や測定値のように値が細かく分かれる連続データでは、まったく同じ値が複数回出ることが少なく、最頻値が偶然の1件で決まってしまいます。連続値では、階級(ビン)に区切ってから「最も度数の多い階級」を見るほうが安定します。
標本によって代表値は変わります。 ここで扱ったのは、あくまで「手元のデータそのもの」を要約する記述統計の話です。その代表値から母集団の中心を推し量る段階に入ると、誤差の評価が必要になり推測統計の領域に移ります。記述と推測の境界は別記事「記述統計とはなにか」を参照してください。
まとめ
平均値・中央値・最頻値は、いずれも「データの中心」を表しますが、定義が異なるため分布が歪むと別々の値を返します。外れ値や歪みがあるなら中央値、左右対称なら平均値、カテゴリや離散値なら最頻値、というのが使い分けの軸です。
実務では平均値と中央値を併記し、そのずれから分布の歪みを察知するのが第一歩になります。計算面では、平均値はどの製品でもAVG / AVERAGEで簡単に求まる一方、中央値・最頻値はSQL方言やBigQuery・Excelで書き方と対応状況が分かれるため、使用する環境ごとの確認が欠かせません。