
データの中には、ほかの値から大きく離れた「外れ値」が混ざることがあります。
外れ値は平均値や標準偏差を大きく動かし、分析結果を誤らせる原因になります。一方で、すべての外れ値が「間違い」とは限らず、安易に削除すると重要な事実を捨ててしまうこともあります。
本稿では、外れ値の定義と異常値との違い、IQRや標準偏差を使った検出方法、そして除外・補正・保持の判断軸を整理し、SQL・BigQuery・Excelでの具体的な検出と除外の書き方(製品差を含む)までを扱います。
この記事で分かること
- 外れ値とはなにか、「異常値」とどう違うのか
- IQR法・標準偏差法など、外れ値を検出する代表的な方法と最短の答え
- 検出した外れ値を「除外・補正・保持」のどれにするかの判断軸
- SQL・BigQuery・Excelで外れ値を検出し、除外前後を比較する方法(製品差を含む)
外れ値とはなにか
外れ値(outlier)とは、データの大多数から大きく離れた値のことです。実務で広く使われる基準は「四分位範囲(IQR)を使い、Q1 − 1.5×IQR より小さい、または Q3 + 1.5×IQR より大きい値を外れ値とみなす」というものです。
たとえば購入金額が {800, 1000, 1200, 1200, 1300, 1500, 30000} の7件なら、30,000円だけが極端に大きく、ほかの値から離れています。この値が外れ値です。
多くの値が1,000円台に集まっているのに、平均値はこの1件に引っ張られて約5,286円まで上がり、データの実態(典型は1,200円前後)を表さなくなります。
外れ値と異常値の違い
「外れ値」と「異常値」は混同されがちですが、見ている視点が異なります。外れ値はあくまで「位置」の話で、分布の中で他から離れているという統計的な性質を指します。
異常値は「原因・正しさ」の話で、入力ミス・測定エラー・単位の取り違えなど、本来あってはならない誤った値を指します。
- 入力ミスで生まれた異常値は、多くの場合そのまま外れ値として現れます(例:年齢欄に「200」)。
- 一方、正しく記録された大口購入や災害時のアクセス急増のように、「外れ値だが異常値ではない」値も存在します。
検出の手順は同じでも、「誤りだから直す・捨てる」のか「正しいデータだから残して扱い方を変える」のかは、現場の知識で判断する必要があります。この区別が、後述する対処法の出発点になります。
外れ値の検出方法
外れ値の検出には、分布の形に依存しにくい順位ベースの方法(IQR法)と、平均・標準偏差を使う方法(zスコア)が代表的です。実務では、まずIQR法から確認すると扱いやすいです。
値の大きさそのものではなく順位をもとに見るため、極端な値に引っ張られにくいからです。
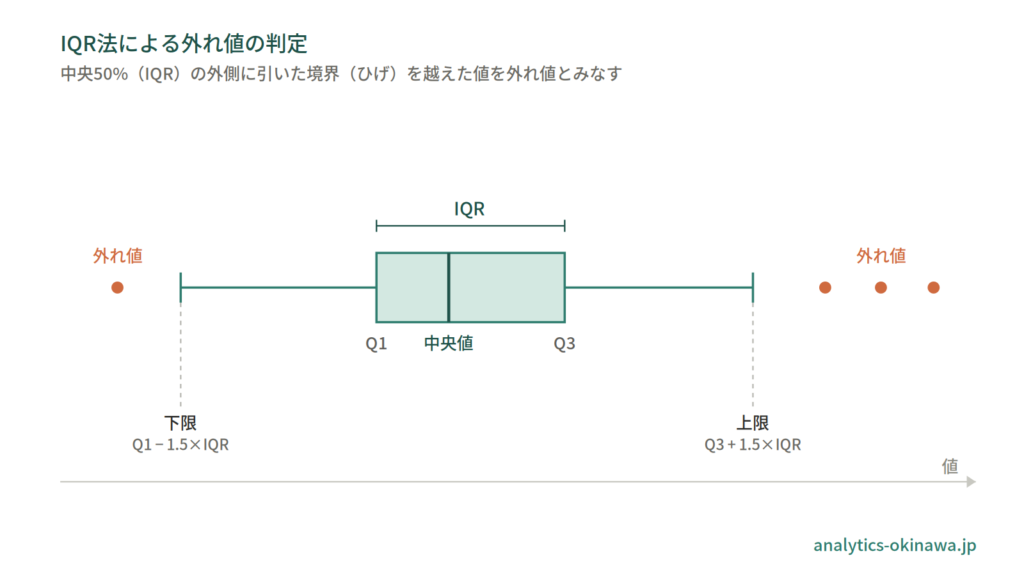
IQR法(四分位範囲)
データを小さい順に並べ、下から1/4の位置の値をQ1(第1四分位数)、3/4の位置をQ3(第3四分位数)とします。
その差 IQR = Q3 − Q1 が中央50%の広がりです。これを使い、下限を Q1 − 1.5×IQR、上限を Q3 + 1.5×IQR とし、その外側にある値を外れ値とみなします。
係数1.5は慣用的な基準で、より厳しく見たいときは 3.0×IQR を使うこともあります(3.0×IQR の外側は「極端な外れ値」と呼ばれます)。
IQR法は順位に基づくため、外れ値そのものに引っ張られにくいのが利点です。箱ひげ図はこのIQR基準を可視化したもので、読み方は別記事で扱います。
標準偏差(zスコア)による方法
分布が概ね左右対称(正規分布に近い)なら、平均からの距離を標準偏差の単位で測るzスコアも使えます。z =(値 − 平均)÷ 標準偏差 とし、|z| > 3(場合により2)を外れ値の目安とします。
ただし注意が必要です。平均と標準偏差そのものが外れ値の影響を受けるため、極端な値が多いデータでは検出力が落ちます。
極端な値の影響を受けにくくしたい場合は、平均の代わりに中央値、標準偏差の代わりにMAD(中央絶対偏差)を使う方法もあります。標準偏差の計算そのものは別記事を参照してください。
| 方法 | 判定の基準 | 向いている場面 | 注意点 |
|---|---|---|---|
| IQR法 | Q1−1.5×IQR 〜 Q3+1.5×IQR の外側 | 分布の形を問わず汎用的 | 1.5は慣用値。閾値は目的で要検討 |
| zスコア法 | |z| > 3 など | 左右対称・正規分布に近い分布 | 平均・標準偏差が外れ値に引っ張られる |
| MAD法(頑健版) | 中央値 ± k×MAD の外側 | 外れ値が多い・歪んだ分布 | 計算がやや複雑になる |
外れ値への対処法
検出した外れ値を機械的に削除するのは危険です。まず「なぜその値が外れているのか」を確認し、原因に応じて対処法を選びます。
判断軸:除外・補正・保持
| 状況 | 対処 | 理由・補足 |
|---|---|---|
| 入力ミス・測定エラーと判明 | 修正、または除外 | 誤りなので分析に残さない。可能なら正しい値に直す |
| 正当な値だが分析目的に影響 | 集計から除外、または頑健な指標を使う | 平均より中央値、IQRなど外れ値に強い指標へ |
| 正当な値で、その挙動自体が分析対象 | 保持する | 不正検知・異常監視などでは外れ値こそ本命 |
| 理由が不明 | 保留し、除外前後の結果を比較 | 影響の大きさを見てから判断する |
「除外」と「欠損値化」は別物
外れ値を除外する際、行ごと削除するのか、その値だけを欠損(NULLや空欄)にして他の列は残すのかで、後段の集計が変わります。値だけを除く場合は欠損値処理の考え方が関わるため、削除・補完・集計除外の選び方は別記事を参照してください。
そして最も重要なのは、外れ値を除外したら必ず「除外前後で結果がどう変わったか」を比較し、レポートに明示することです。除外は分析者の判断であり、結果を恣意的に動かしうるためです。
SQL・BigQuery・Excelで外れ値を検出・除外する
ここではIQR法を例に、各環境での書き方を示します。考え方は共通で、(1) Q1・Q3を求める →(2)IQRと上下限を計算 →(3)WHERE などで範囲外を抽出または除外する、の3段階です。
SQL(PostgreSQL)
PostgreSQLでは PERCENTILE_CONT でQ1・Q3を求め、CTEで上下限を計算してから抽出します。
-- PostgreSQL:IQR法で外れ値を抽出
WITH q AS (
SELECT
PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY amount) AS q1,
PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY amount) AS q3
FROM purchases
),
b AS (
SELECT q1, q3,
q1 - 1.5 * (q3 - q1) AS lower,
q3 + 1.5 * (q3 - q1) AS upper
FROM q
)
SELECT p.*
FROM purchases p, b
WHERE p.amount < b.lower OR p.amount > b.upper; -- 外れ値だけを抽出外れ値を除外(範囲内だけを残す)したい場合は、最後の条件を WHERE p.amount BETWEEN b.lower AND b.upper に変えます。PERCENTILE_CONT は補間を含む連続版の分位数で、PostgreSQL 9.4以降で利用できます。
なお、BETWEEN で範囲内に絞ると amount が NULL の行は結果から落ちます(NULL は大小比較が成立しないため、範囲内とも範囲外とも判定されません)。
欠損のある列で外れ値を除外するときは、NULL行をどう扱うか(残す・別集計する・補完する)を別途決める必要があります。考え方は別記事「欠損値処理とはなにか|削除・補完・集計除外の考え方」を参照してください。
SQL(製品差)
分位数を求める関数は方言差が大きい領域です。標準SQLに共通の四分位関数があるわけではなく、製品ごとに書き方が分かれます。
| 製品 | Q1・Q3の求め方 |
|---|---|
| PostgreSQL | PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY x) |
| SQL Server | PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY x) OVER ()(ウィンドウ関数) |
| MySQL | 専用の分位数集約なし(8.0のウィンドウ関数や行番号・NTILEで代替) |
MySQLのように専用の分位数集約がない環境では、NTILE や行番号で四分位の位置を求めるなどの代替が必要です。最終的な構文は使用する製品で検証してください。
BigQuery
BigQueryには集約関数としての MEDIAN / PERCENTILE がなく、近似分位の APPROX_QUANTILES を使うのが基本です。ここでは PostgreSQL と同様に、CTEで上下限を計算し、WHERE で範囲外を除外します。
-- BigQuery:IQR法で外れ値を除外(近似分位)
WITH b AS (
SELECT
APPROX_QUANTILES(amount, 4)[OFFSET(1)] AS q1,
APPROX_QUANTILES(amount, 4)[OFFSET(3)] AS q3
FROM purchases
)
SELECT p.*
FROM purchases p, b
WHERE p.amount BETWEEN b.q1 - 1.5 * (b.q3 - b.q1)
AND b.q3 + 1.5 * (b.q3 - b.q1); -- 外れ値を除外APPROX_QUANTILES(amount, 4) は4分割の境界を返し、OFFSET(1) がQ1、OFFSET(3) がQ3です。これは近似値である点に注意してください。
厳密な分位が必要なら PERCENTILE_CONT(amount, 0.25) OVER () をウィンドウ関数として使えますが、大規模テーブルでは計算コストが上がります。またBigQuery はスキャンした列のデータ量に応じて課金されるため、対象の列・期間・WHERE 条件を絞ってスキャン量を抑えるのが基本です。
補足:上の例は CTE と WHERE で完結するため QUALIFY は使いません。ウィンドウ関数で求めた分位を、サブクエリを作らずに同じ階層で直接フィルタしたい場合は、BigQuery 独自の QUALIFY 句(例: … QUALIFY amount BETWEEN … AND … )が使えます。ただし QUALIFY は標準SQL全般で使えるわけではなく、対応する製品が限られる点に注意してください。
Excel
Excelは関数で四分位を直接求められ、最も手軽です。
| 項目 | Excel 関数 / 操作 |
|---|---|
| Q1 | =QUARTILE.INC(範囲, 1) |
| Q3 | =QUARTILE.INC(範囲, 3) |
| IQR | =QUARTILE.INC(範囲,3) - QUARTILE.INC(範囲,1) |
| 下限・上限 | =Q1 - 1.5*IQR / =Q3 + 1.5*IQR |
| 外れ値の判定 | =OR(セル<下限, セル>上限) を各行に置く |
QUARTILE.INC は両端を含む(inclusive)方式、QUARTILE.EXC は両端を除く(exclusive)方式で、四分位の定義が異なります。どちらを使うかでQ1・Q3がわずかに変わるため、統一して使ってください。
検出した外れ値を視覚的に強調したいときは、上限・下限を条件にした条件付き書式(「数式を使用してルールを設定」)でセルを色分けすると、表のまま確認できます。
注意点
1.5×IQRは絶対基準ではありません。 これは経験則であり、業務やデータによっては緩すぎたり厳しすぎたりします。閾値を変えれば検出件数も変わるため、基準は目的に合わせて決め、明示します。
外れ値=削除ではありません。 外れ値は「確認すべき値」であって「捨てるべき値」ではありません。原因を確かめずに削除すると、不正・故障・重要顧客といった本来見るべき事実を見落とします。
近似と厳密を区別します。 BigQueryの APPROX_QUANTILES は高速ですが近似値です。報告時にはどちらを使ったかを明示すると誤解を避けられます。
多変量の外れ値は1列だけでは見つかりません。 各列単独では正常でも、組み合わせると異常な行(例:身長150cmで体重100kg)があります。本稿の手法は1列(単変量)の検出が中心で、多変量はより高度な手法が必要です。
まとめ
外れ値は、データの大多数から大きく離れた値です。
検出にはIQR法が汎用的で頑健、左右対称な分布ならzスコアも使えますが、平均・標準偏差が外れ値に引っ張られる点に注意します。検出後は機械的に削除せず、入力ミスなら修正・除外、正当な値なら頑健な指標へ切り替えるか保持するなど、原因に応じて対処を選び、除外前後の結果を必ず比較・明示します。
計算面では、Q1・Q3さえ求めれば手順は共通ですが、分位数関数はSQL方言・BigQuery・Excelで書き方と近似/厳密の差があるため、環境ごとの検証が欠かせません。