
データ分析の最初の分かれ道は、その列が「計算してよい数値」か「数えるだけのカテゴリ」かを見分けることです。この記事を読むと、量的変数と質的変数を具体例で区別でき、それぞれに合った集計(量的は平均・標準偏差、質的は GROUP BY・件数)を選べるようになります。
郵便番号や会員IDのように「数値の見た目をした質的変数」を取り違えない判断軸も押さえます。
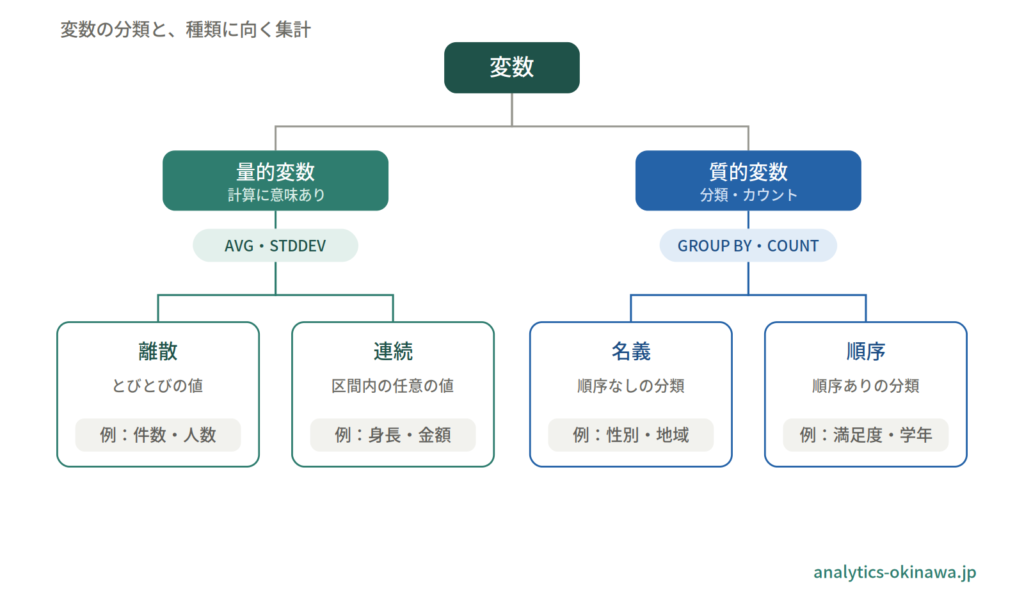
違いは「計算に意味があるか」で分かる
量的変数(quantitative)=大きさを数値で測り、平均・差・合計などの数値計算に意味がある変数。例:点数、金額、人数、身長。
質的変数(qualitative/カテゴリ変数)=種類や分類を表し、計算ではなく分類・カウントの対象になる変数。例:性別、地域、商品カテゴリ、血液型。
見分け方はひとつだけ覚えれば十分です。その列に平均・差・合計といった数値計算をして、分析上の意味が出るなら量的、出ないなら質的です。
テストの点数は平均すると「クラスの平均点」という意味を持ちますが、地域コードを平均しても何の意味もありません。集計の種類(平均か、カウントか)がそのまま変数の種類に対応します。
量的変数の中身:離散と連続
量的変数は、取りうる値のあり方でさらに二つに分かれます。
離散変数は、とびとびの値しか取らない量です。注文件数、来店人数、不良品の個数などが該当します。「3.5件の注文」は存在しないように、値が整数などの飛び飛びの点に限られます。
連続変数は、区間内のどんな値も取りうる量です。身長、体重、所要時間、気温などが該当します。測定の精度を上げればいくらでも細かく刻める(170cmと171cmの間に170.4cmがある)のが連続変数の特徴です。
実務では金額や売上を連続変数として扱うことがよくあります。厳密には金額は1円刻みの離散ですが、値の幅が広く刻みが細かいため、平均・標準偏差・ヒストグラムといった連続量向けの要約がそのまま有効に働くからです。
この「厳密には離散だが実務上は連続として扱う」感覚は、後で集計方法を選ぶときに効いてきます。
質的変数の中身:名義と順序
質的変数も二つに分かれます。区別の鍵は「カテゴリの間に順序があるか」です。
名義変数は、順序のないカテゴリです。性別、都道府県、血液型、商品ジャンルなど、並べ替えても優劣・大小が生じない分類がこれにあたります。
順序変数は、順序のあるカテゴリです。満足度(不満/普通/満足)、サイズ(S/M/L)、成績評価(C/B/A)などで、順番には意味がありますが、隣り合う段階の「間隔」が等しいとは限りません。満足度の「普通→満足」と「不満→普通」が同じ幅の改善だとは言えない、という点が量的変数との決定的な違いです。
この名義・順序という区別は、さらに「尺度水準(名義・順序・間隔・比例)」という枠組みへ広がります。間隔尺度・比例尺度まで含めた4段階の整理は別記事に譲りますが、まずは「質的=名義か順序」「量的=間隔か比例に対応」と対応づけて捉えておくと、この記事の判断には十分です。
一覧で対応づける
| 大分類 | 小分類 | 性質 | 具体例 | 代表的な集計 |
|---|---|---|---|---|
| 量的変数 | 離散 | とびとびの値 | 注文件数、来店人数、不良品数 | 合計・平均・件数 |
| 量的変数 | 連続 | 区間内の任意の値 | 身長、所要時間、金額(実務上) | 平均・標準偏差・ヒストグラム |
| 質的変数 | 名義 | 順序なしの分類 | 性別、地域、血液型、商品ジャンル | 件数・構成比・最頻値 |
| 質的変数 | 順序 | 順序ありの分類 | 満足度、サイズ、成績評価、学年 | 件数・中央値(順位として)・クロス集計 |
SQL・BigQuery・Excel での確認
変数の種類は、集計操作の選び方にそのまま直結します。量的変数は「数値を要約する関数」、質的変数は「グループに分けて数える操作」が基本です。
SQL:量的は集計関数、質的は GROUP BY
量的変数(数値列)は、平均・標準偏差・最小最大といった集計関数で要約します。以下は標準SQL(PostgreSQL / BigQuery 系)を前提にしています。実行時はお使いの環境・版で動作を確認してください。
SQL — 量的変数(点数)を要約する
-- 量的変数(点数)を要約する
SELECT
COUNT(*) AS n, -- 件数
AVG(score) AS mean, -- 平均(中心)
STDDEV_SAMP(score) AS sd, -- 標準偏差(ばらつき)
MIN(score) AS min_val,
MAX(score) AS max_val
FROM exam_results;質的変数(カテゴリ列)は、平均ではなく「カテゴリごとに数える」ことで要約します。GROUP BY と COUNT が基本の組み合わせです。
SQL — 質的変数(地域)をカテゴリ別に数える
-- 質的変数(地域)をカテゴリ別に数える
SELECT
region, -- 名義変数
COUNT(*) AS n, -- 件数
ROUND(100.0 * COUNT(*) / SUM(COUNT(*)) OVER (), 1) AS pct -- 構成比(%)
FROM customers
GROUP BY region
ORDER BY n DESC;「その列が量的か質的か」を判断する材料として、異なる値の種類数(カーディナリティ)を見るのも実務的な手です。COUNT(DISTINCT col) の結果が数件しかなければ、たとえ数値型でもカテゴリとして扱うのが自然です。
SQL — 列のユニーク値数を見て、カテゴリかどうかの当たりをつける
-- 列のユニーク値数を見て、カテゴリかどうかの当たりをつける
SELECT COUNT(DISTINCT grade) AS unique_grades -- 例: 学年 → 数件ならカテゴリ寄り
FROM students;標本標準偏差は PostgreSQL / BigQuery / MySQL では STDDEV_SAMP、SQL Server では STDEV を使います(母標準偏差は PostgreSQL / BigQuery が STDDEV_POP、SQL Server が STDEVP)。COUNT(DISTINCT ...) は4製品とも使えますが、BigQuery で大規模データを高速に概算したい場合は APPROX_COUNT_DISTINCT が選べます。関数名の差は意味の差ではない点に注意してください。
BigQuery:スキーマの型に引きずられない
BigQuery では列に INT64 / FLOAT64 / NUMERIC / STRING などの型が付きますが、型が数値(INT64)でも、それが量的変数だとは限りません。会員ID・郵便番号・店舗コードは INT64 で格納されていても質的変数です。
スキーマの型は格納方法であって、統計的な変数の種類とは別物だと切り分けてください。判断には、前述の COUNT(DISTINCT col)(または APPROX_COUNT_DISTINCT(col))でユニーク値数を確認し、値の幅・刻みと合わせて見るのが確実です。
数値型の列が「実はカテゴリ」かどうかは、ユニーク値数を見れば当たりがつきます。大規模データなら近似関数 APPROX_COUNT_DISTINCT が高速です。
BigQuery — 数値型の列のユニーク値数を確認する
-- 数値型の列のユニーク値数を確認し、量的か質的かを見極める
SELECT
APPROX_COUNT_DISTINCT(store_code) AS unique_stores, -- 店舗コード(数値型だが質的)
APPROX_COUNT_DISTINCT(member_id) AS unique_members, -- 会員ID(数値型だが質的)
COUNT(*) AS rows_all
FROM sales;unique_stores が数十、unique_members が行数に近い、といった結果になれば、いずれも平均する対象ではなく GROUP BY で数える質的変数だと判断できます。
Excel:量的は関数、質的はピボット
Excel では、量的変数は AVERAGE / STDEV.S / MEDIAN などの関数で要約し、質的変数はピボットテーブルでカテゴリ別の件数を集計するのが最短です。
特定カテゴリの件数だけなら COUNTIF が使えます。値の種類数(重複を除いたユニーク数)は、COUNTA だけでは求まりません(COUNTA は空白以外の件数を数える関数です)。
Excel 365 なら COUNTA(UNIQUE(範囲)) で重複を除いた種類数を得られます。少量データの探索や、クエリ結果を貼り付けての最終確認に向いています。
| 変数の種類 | 向く操作 | SQL | BigQuery | Excel |
|---|---|---|---|---|
| 量的(中心) | 平均 | AVG() | AVG() | AVERAGE |
| 量的(ばらつき) | 標準偏差 | STDDEV_SAMP() | STDDEV_SAMP() | STDEV.S |
| 質的 | カテゴリ別件数 | GROUP BY + COUNT(*) | GROUP BY + COUNT(*) | ピボット / COUNTIF |
| 質的 | 値の種類数 | COUNT(DISTINCT col) | APPROX_COUNT_DISTINCT(col) | ピボット / COUNTA(UNIQUE())(365) |
落とし穴:数値の見た目をした質的変数
実務でいちばん事故が多いのが、数値で格納されているのに中身は質的変数というケースです。
- コード化されたカテゴリ:性別を「1=男性, 2=女性」、満足度を「1〜5」のように数値コードで持つ列。
AVG(gender_code)は「1.5」のような無意味な値を返します。集計してはいけません。 - 識別子・番号:会員ID、郵便番号、電話番号、店舗コード。数値型でも大小・平均に意味はなく、これらは名義変数です。郵便番号の平均は地理的に何も表しません。
- 順序変数の平均:満足度(1〜5)の平均は現場で広く使われますが、これは「段階の間隔が等しい」という仮定を置いた便宜的な扱いです。厳密には順序変数なので、平均値だけでなく、1〜5それぞれの件数分布(1がどれだけ多いか、5に偏っていないか)も併せて見るのが安全です。平均が同じ「3.0」でも、全員が3を付けたのか、1と5が半々なのかで意味はまったく異なります。
判断に迷ったら、「この列に平均・差・合計などの計算をして意味が出るか」を自問してください。意味が出なければ、型が数値でも質的変数として GROUP BY 側で扱います。逆に、見た目が文字列でも本来は量的なケース(例:"1,200" のようにカンマ区切りで文字列として入った金額)もあり、その場合は数値へ変換してから集計します。型変換の具体的な方法は型変換の記事に譲ります。
まとめ
量的変数と質的変数の違いは、「平均・差・合計などの数値計算に意味があるか」の一点に集約されます。量的変数は離散と連続に分かれ、AVG・STDDEV などの集計関数で要約します。質的変数は名義と順序に分かれ、GROUP BY と COUNT でカテゴリ別に数えます。
最大の注意点は、郵便番号や数値コードのように「数値型だが質的」な列を平均してしまわないこと。型ではなく意味で見分け、変数の種類に合った集計を選ぶ——これがデータを正しく要約する出発点です。