
データ分析でいちばん最初に意識すべきなのは、「いま手元にあるデータは、知りたい対象の全部なのか、一部なのか」という区別です。
この記事を読むと、母集団(知りたい対象の全体)と標本(実際に観測した一部)を具体例で区別でき、なぜ全体ではなく一部を抜き出すのか、その一部をどう抜き出すべきか(属性で絞るのか、乱数で縮図を作るのか)が分かります。
あわせて、SQL・BigQuery・Excel での実際のサンプリング操作と、その落とし穴も押さえます。
違いは「全体か、その一部か」で分かる
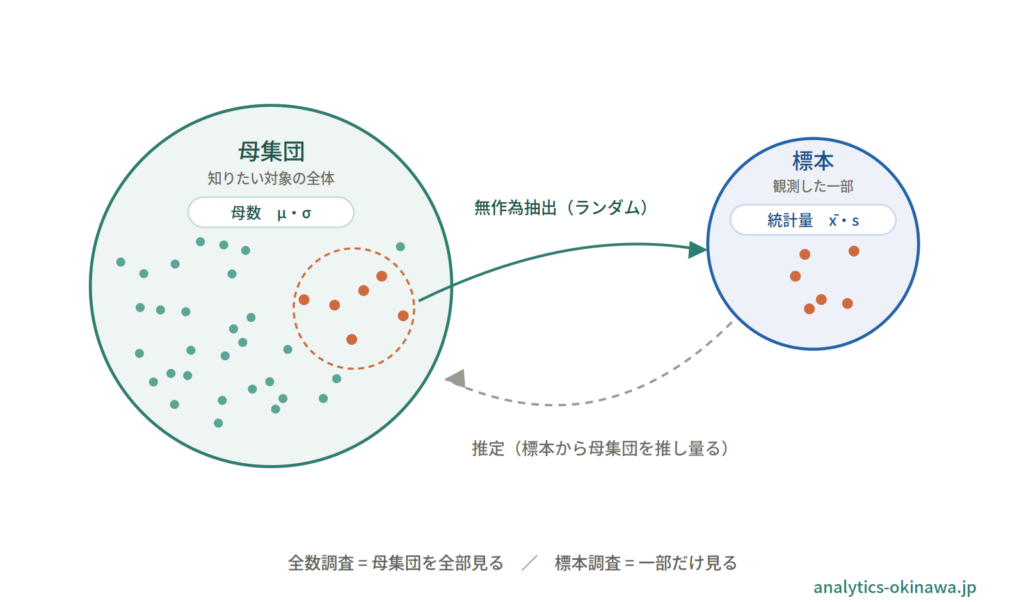
- 母集団(population)=本当に知りたい対象の全体。例:自社の全顧客、ある製品の全ロット、日本の有権者全員。
- 標本(sample/サンプル)=母集団から実際に抜き出して観測した一部。例:全顧客のうち抽出した1万人、全ロットから取り出した検査品、世論調査で回答した2,000人。
区別はひとつだけ覚えれば十分です。「最終的に結論を当てはめたい対象の全体」が母集団、「その結論を導くために実際に手元で見ているデータ」が標本です。全顧客の平均購入額を知りたい(=母集団は全顧客)が、計算が重いので無作為に抜き出した1万人で平均を出す、というとき、この1万人が標本にあたります。
ここで大事なのは、母集団は「データの量」ではなく「問いの範囲」で決まるという点です。同じ顧客テーブルでも、「全顧客の傾向を知りたい」なら母集団は全顧客、「東京都の顧客の傾向を知りたい」なら母集団は東京都の顧客に変わります。何を知りたいかが母集団を定義し、その一部として標本がある、という順序で考えます。
なぜ全体ではなく一部(標本)を見るのか
全部を調べる方法(全数調査)が常に可能なら、標本は要りません。それでも標本を取るのは、主に次の理由からです。
ひとつはコストと時間です。数億行のログ全件に重い集計をかけるより、代表的な一部で傾向をつかむほうが速く安く済みます。もうひとつは全数調査が原理的に不可能な場合です。製品の破壊検査(壊して調べる検査)では全数を検査したら売る物がなくなりますし、「これから来る未来の顧客」までは数えられません。
つまり標本は、手間を減らしつつ、母集団について十分な精度で語るための手段です。だからこそ「その一部が母集団の縮図になっているか」が決定的に重要になります。
母数(パラメータ)と統計量の対応
母集団と標本を分けると、そこから計算される値も二種類に分かれます。混同しやすいので記号ごと整理します。
| 対象 | 値の呼び方 | 平均 | 標準偏差 | 性質 |
|---|---|---|---|---|
| 母集団 | 母数(パラメータ) | μ(ミュー) | σ(シグマ) | 本来知りたい真の値。通常は直接わからない |
| 標本 | 統計量 | x̄(エックスバー) | s | 手元のデータから計算できる値。母数の推定に使う |
母数(パラメータ)は「知りたいが直接は見えない真の値」、統計量は「標本から実際に計算できる値」です。データ分析の多くは、見えない母数(μ や σ)を、計算できる統計量(x̄ や s)から推し量る作業だと言えます。標本から母集団を推し量るこの考え方が推測統計であり、その精度を区間で表すのが信頼区間です。本記事ではこの接続を示すにとどめ、詳細は推測統計・信頼区間の記事に譲ります。
この母集団/標本の区別は、関数の選択にも直接効いてきます。標準偏差には、母集団全体を前提にした母標準偏差と、標本から母集団のばらつきを推定する標本標準偏差があります。標本標準偏差では、分散を計算する段階で n−1 で割る不偏分散を使います。手元のデータが母集団そのものなのか、より大きな母集団からの標本なのかで、選ぶ関数が変わります。
SQL・BigQuery・Excel での確認
実務では「全件テーブル(母集団に相当)から、一部を抜き出して(標本にして)分析する」場面が頻繁にあります。ここで特に重要なのが、属性で対象(母集団)そのものを変えているのか、乱数で母集団の縮図(標本)を作っているのかという区別です。
これは WHERE という構文の有無では分けられません。たとえば後述の WHERE RAND() < 0.1 は WHERE を使いますが、属性ではなく乱数で抜き出しているため、これはランダムサンプリングにあたります。見るべきは構文ではなく、条件の性質(属性条件か乱数条件か)です。
- 属性条件による抽出:「東京都の顧客だけ」のように、属性(地域・期間・区分など)で対象を絞り込む操作。これは標本づくりではなく、母集団そのものの定義変更です。
- 乱数条件によるサンプリング:属性では絞らず、乱数を使って母集団の縮図となる一部を無作為に抜き出す操作。母集団を推し量るための標本づくりです。
「全顧客から一部の行動ログを抽出して分析する」とき、速度のために縮図を取るなら乱数条件のサンプリング、特定セグメントだけを見たいなら属性条件の抽出、と目的で使い分けます。
SQL:ランダム抽出と TABLESAMPLE
母集団に相当する全件テーブルから、無作為に一定件数を抜き出す最も直感的な方法は、乱数で並べ替えて先頭から取る書き方です。乱数関数名も件数制限の構文も製品ごとに異なるため、製品をまたいでコメントで一括りにはできません。PostgreSQL と MySQL は LIMIT を使います(乱数関数は PostgreSQL が RANDOM()、MySQL が RAND())。
SQL Server は件数制限に LIMIT を持たず TOP を使い、乱数並べ替えは NEWID() で行います。構文が異なるため別に示します。
この書き方は行単位の無作為抽出として分かりやすいですが、全行に乱数を振って並べ替えるため、大規模テーブルでは重くなりやすいという弱点があります。そこで、近似的に高速サンプリングする標準SQLの構文が TABLESAMPLE です。
SQL – PostgreSQL:乱数で並べ替えて先頭1000件を標本にする
SELECT *
FROM customers
ORDER BY RANDOM()
LIMIT 1000;SQL – MySQL:乱数で並べ替えて先頭1000件を標本にする
SELECT *
FROM customers
ORDER BY RAND()
LIMIT 1000;SQL – SQL Server:LIMITではなくTOP、乱数並べ替えはNEWID()
SELECT TOP (1000) *
FROM customers
ORDER BY NEWID();SQL – PostgreSQL:テーブルのおよそ10%を抽出する
SELECT *
FROM customers
TABLESAMPLE SYSTEM (10); -- 「およそ10%」。厳密な10%・厳密な無作為ではないここで製品差と精度の注意があります。TABLESAMPLE SYSTEM は行単位ではなくデータの格納ブロック単位で抽出する近似方式で、速い代わりに、隣り合う行が偏って入っていると標本も偏ります。PostgreSQL には行単位で抽出する TABLESAMPLE BERNOULLI (10) もあり、こちらはより無作為に近い代わりに低速です。
なお TABLESAMPLE は MySQL では使えません(ORDER BY RAND() で代替します)。条件で母集団を切り替えたいだけなら、サンプリングではなく通常の WHERE を使います。
SQL – 属性条件による母集団の定義変更
SELECT *
FROM customers
WHERE prefecture = '東京都'; -- 母集団が「東京都の顧客」に変わるBigQuery:TABLESAMPLE SYSTEM と RAND()
BigQuery では、スキャン量とコストを抑えるサンプリングとして TABLESAMPLE SYSTEM が使えます。割合の指定に PERCENT キーワードが必要な点が他製品と異なります。
行単位でより無作為に近い抽出をしたい場合は、RAND()(0以上1未満の乱数を返す関数)を条件に使う方法があります。こちらは全行に乱数を評価するためフルスキャンになり、TABLESAMPLE のようなスキャン量削減の効果はない点に注意してください。
件数をきっちり指定したいときは ORDER BY RAND() LIMIT n も書けますが、全件の並べ替えが発生するため大規模データでは高コストです。「スキャン量を減らしたい」のか「厳密な無作為性が欲しい」のかで TABLESAMPLE SYSTEM と RAND() を選び分けます。
SQL – BigQuery:テーブルのおよそ10%をブロック単位で抽出する
SELECT *
FROM `project.dataset.events`
TABLESAMPLE SYSTEM (10 PERCENT); -- ブロック単位の近似サンプリングSQL – BigQuery:行単位でおよそ10%を無作為抽出する
SELECT *
FROM `project.dataset.events`
WHERE RAND() < 0.1; -- 各行を10%の確率で採用(フルスキャンになる)Excel:条件抽出は FILTER、無作為抽出は RAND 系
Excel では目的によって関数が分かれます。条件で絞る抽出(母集団の切り替え)は FILTER、無作為抽出(標本づくり)は乱数を使います。いずれもスピル機能のある Excel 365 / Web 版が前提です。
条件抽出は FILTER が最短です。
Excel – 条件抽出
=FILTER(A2:D10000, C2:C10000="東京都")無作為抽出は、乱数で並べ替えて先頭から取るのが分かりやすい方法です。SORTBY と RANDARRAY を組み合わせ、必要件数を TAKE(または上位n行参照)で取り出します。
Excel – 無作為抽出
=TAKE(SORTBY(A2:D10000, RANDARRAY(ROWS(A2:D10000))), 100)RAND() は再計算のたびに値が変わる(揮発性)ため、抽出結果を固定したい場合は、RAND() で振った乱数列を「値として貼り付け」してから並べ替えると安定します。少量データの探索や、クエリ結果を貼り付けての最終確認に向いています。
| 目的 | 操作の種類 | SQL | BigQuery | Excel(365) |
|---|---|---|---|---|
| 条件で絞る | 母集団の切替(≠標本) | WHERE | WHERE | FILTER |
| 割合で高速抽出 | 近似サンプリング | TABLESAMPLE SYSTEM (10) | TABLESAMPLE SYSTEM (10 PERCENT) | (該当なし/乱数で代替) |
| 件数を指定して無作為抽出 | ランダムサンプリング | ORDER BY RANDOM() LIMIT n(SQL Serverは SELECT TOP (n) … ORDER BY NEWID()) | ORDER BY RAND() LIMIT n | TAKE(SORTBY(範囲,RANDARRAY(…)),n) |
| 標本の標準偏差 | 統計量(n−1) | STDDEV_SAMP() | STDDEV_SAMP() | STDEV.S |
| 母集団の標準偏差 | 母数(n) | STDDEV_POP() | STDDEV_POP() | STDEV.P |
落とし穴:偏った一部を母集団の縮図と思い込む
母集団と標本まわりで実務の事故が多いのは、「一部を抜き出した」ことと「母集団を代表できる」ことを混同するケースです。
第一に、属性条件による抽出を標本だと思い込む間違いです。「東京都の顧客だけ」を属性条件で抜き出した結果から「全顧客はこうだ」と語ると、母集団がすり替わっています。
これは標本の偏り(選択バイアス)の典型で、乱数による無作為抽出にすれば選択バイアスを抑えやすくなります。一部を取るときは「属性で母集団を変えたのか/乱数で縮図を作ったのか」を毎回意識してください。
第二に、TABLESAMPLE SYSTEM のブロック単位サンプリングは厳密な無作為ではないという点です。データが日付順や地域順に固まって格納されていると、抽出される標本も特定の塊に偏ることがあります。厳密性が必要なら、行単位の BERNOULLI(PostgreSQL)や RAND() 条件(BigQuery)を検討します。
第三に、標本の標準偏差と母集団の標準偏差を取り違えることです。手元のデータがより大きな母集団からの標本なら標本標準偏差(STDDEV_SAMP / STDEV.S、n−1で割る)、手元のデータ自体が母集団の全件なら母標準偏差(STDDEV_POP / STDEV.P、nで割る)を使います。
どちらを選ぶかは「このデータは母集団か標本か」という、本記事の区別そのものに依存します。
判断に迷ったら、「いま見ているデータは、結論を当てはめたい対象の全部か、一部か」「一部なら、それは縮図(無作為)か、別の母集団(条件抽出)か」を自問してください。
まとめ
母集団と標本の違いは、「結論を当てはめたい対象の全体か(母集団)、実際に観測した一部か(標本)」の一点に集約されます。母集団は問いの範囲で決まり、標本はそれを推し量るための縮図です。
母集団からは母数(μ・σ)、標本からは統計量(x̄・s)が対応し、データ分析の多くは見えない母数を統計量から推定する作業になります。実装では、属性で母集団を切り替える抽出(属性条件の WHERE / FILTER)と、縮図を作る無作為抽出(TABLESAMPLE / RAND 系)は目的の異なる別の操作です。
WHERE という構文の有無ではなく、条件が属性か乱数かで見分けます。一部を抜き出すときは「属性で母集団を変えたのか、乱数で縮図を作ったのか」を区別する——これが、手元のデータから正しく全体を語るための出発点です。